#25 Operationalizing Data Pipelines
Subscribe to get the latest
on Tue Oct 13 2020 17:00:00 GMT-0700 (Pacific Daylight Time)
with Darren W Pulsipher, Sarah Kalicin,
Darren Pulsipher, Chief Solutions Architect, Public Sector, Intel, talks to Sarah Kalicin, Lead Data Scientist, Intel about operationalizing your organization’s data pipeline. It takes a team effort to model, monitor, and produce an ongoing source of valuable information. This is the final episode in the series Kick-starting your Organizational Transformation to Become Data-Centric.
Keywords
#dataarchitecture #datacentric #data #datamesh #datapipeline #technology #people
Listen Here
For the final episode in this series, Darren talks to Sarah Kalicin, Lead Data Scientist at Intel, about operationalizing your data pipeline. They discuss how, once you have your data insights, you can turn them from a one-time science experiment to an ongoing source of information.
How do we Operationalize Analytics’ Insights?
The first thing to understand about the data pipeline is that it is not like an enclosed electrical system that you can set up, walk away from, and six months later flip a switch and know the bulb will light up. A data pipeline is different in that the data is variable; it can change or degrade, for example, so you will not necessarily be rewarded with the bulb lighting up at any point, or in this case, the insight you are looking for. You always have to be thinking of what can go wrong in the system and how to correct these short-circuits.
Detecting abnormalities is an integral part of the pipeline. You can’t plan for everything, so you at least need to be able to see when something has happened that is outside the bounds of the original analytics. An example is the COVID crisis, an unpredictable event that caused patterns well outside the norm for many systems. Another example would be a company producing widgets. In order to know how many widgets to produce, the data pipeline contains customer demand, current supply, and yield loss. These may be fairly stable over time, but there could be, for instance, a PR event that causes customer demand to explode. That could have a big impact on the models. Machine learning and deep learning look at familiar patterns, and if they have never seen these patterns before, the models are going to fail or degrade. You have to stay on the edge of discovery.
The only way to stay on the edge of discovery is to have your data pipelines automated for timely access to information. This is the competitive advantage: current and insightful data that can help you quickly resolve your questions.
IT teams and data teams need to collaborate on automation and determine what should be automated for incoming data, and on managing any changes to the model that the data scientists want to make so it can be easily integrated back into the workflow.
Deployment Short Circuits
There are two types of controls that can prevent deployment short circuits: Analytic system controls and organizational controls.
Analytic system controls is about putting the models that you have trained to work, feeding data through to easily answer your questions. These deployed models must be moderated to check for accuracy of the data. Many things can cause the data to be adversely affected such as environmental change, machine calibration, distribution problems, and so on.
This isn’t so different from the software development world where changes can affect predictions. The IT department is familiar with the process of running tests to make sure that their models or applications are running according to established guidelines, so dev ops and data scientists should take advantage of these resources and knowledge. There is no need to invent any new process, but instead, the groups should blend resources together to set themselves up for success.
Organizational controls go back to having an organizational foundation which is committed to being data-centric and providing the right people and resources to work together for common goals. The best chance for obtaining operationalization is when there is collaboration, trust, understanding of needs, and feedback loops among the groups in the organization.
Feedback loops are critical in this process. For example, subject matter specialists can provide information about market dynamics so the data scientists can monitor the model for these changes in data. If a model is going to be used over time, it will constantly need to be iterated and improved.
Consumers of the data should have a dashboard the gives them information and allows them to dig into why something looks a little bit off. The more they can investigate, or bring up what needs to be investigated, the more empowered your organization is going to be.
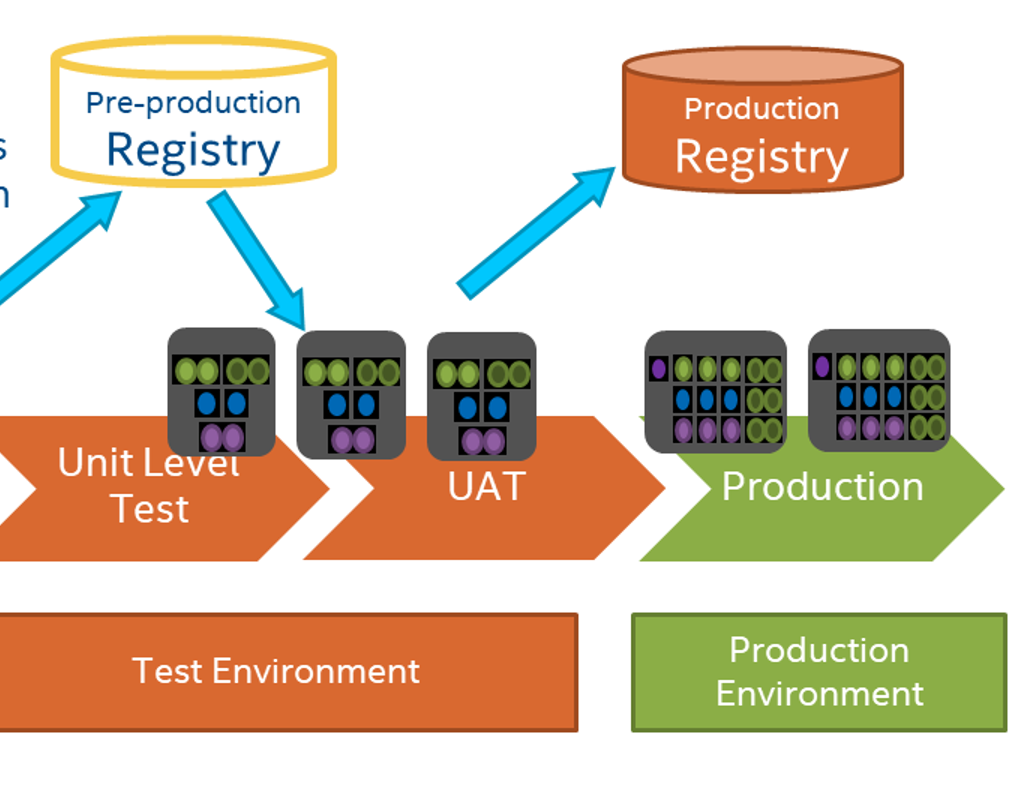
Pipeline
One key from the IT side to help operationalize the data pipeline is to use a version control such as GitHub so you can have access to previous versions of your model. For auditing purposes, the ability to store the data that created the model and other historical data is important as well. You want to be able to look at the patterns and see how a certain feature changed or impacted the model. You can also plug historical data into your new models to see how much it impacts your current data.
For example, some systems will have a skewed picture with a great number of people working from home during COVID. A case in point is the Navy. Since COVID, 95% of their IT workers are remote, and their productivity has gone up 35%. From that one data point, you could say, everyone’s going to work from home from now on. Will you continue to get a 35% increase, or if people come back in the office, will you see a 35% decrease? Obviously, that one data point is not necessarily sufficient to predict actual productivity.
Another tool IT can offer is continuous integration and deployment. Using Jenkins or GitHub Actions or a similar tool when working on a model, you can automatically run tests against your model with your data or generate garbage data on the fly.
The IT people and data scientists need to collaborate on what and how to monitor the output of the models. IT can monitor output automatically, and they can also monitor how the models are performing in the infrastructure. One example is that IT, with automated continuous integration deployment, can quickly alert the data scientists when a model is taking longer than the norm to keep it from spinning out of control. If IT is invested in data value creation, which has generally been missing in the industry as a whole, the process will be easier and more coherent for everyone.
Another aspect to think about is design of experiments because interactions among variables and features are important as well. Subject matter experts can help determine what the potential interactions are, and you can model those to help understand what variability can be expected.
It’s exciting that a data scientist can take raw material and turn it into insight. It does, however, take a team. The more everyone in your organization can learn from each other in a team environment, the more great things can happen.