#18 Data Collection and Preparation
Subscribe to get the latest
on Sun Aug 30 2020 17:00:00 GMT-0700 (Pacific Daylight Time)
with Darren W Pulsipher,
Sarah Kalicin, Lead Data Scientist at Intel and Darren Pulsipher, Chief Solution Architect, Public Sector at Intel talk about the process and benefits of data collection and preparation in becoming a data-centric organization. This is step two in the journey of becoming a data-centric organization.
Keywords
#dataarchitecture #datacentric #data
Listen Here
We Need Data! Our Data is a Mess!
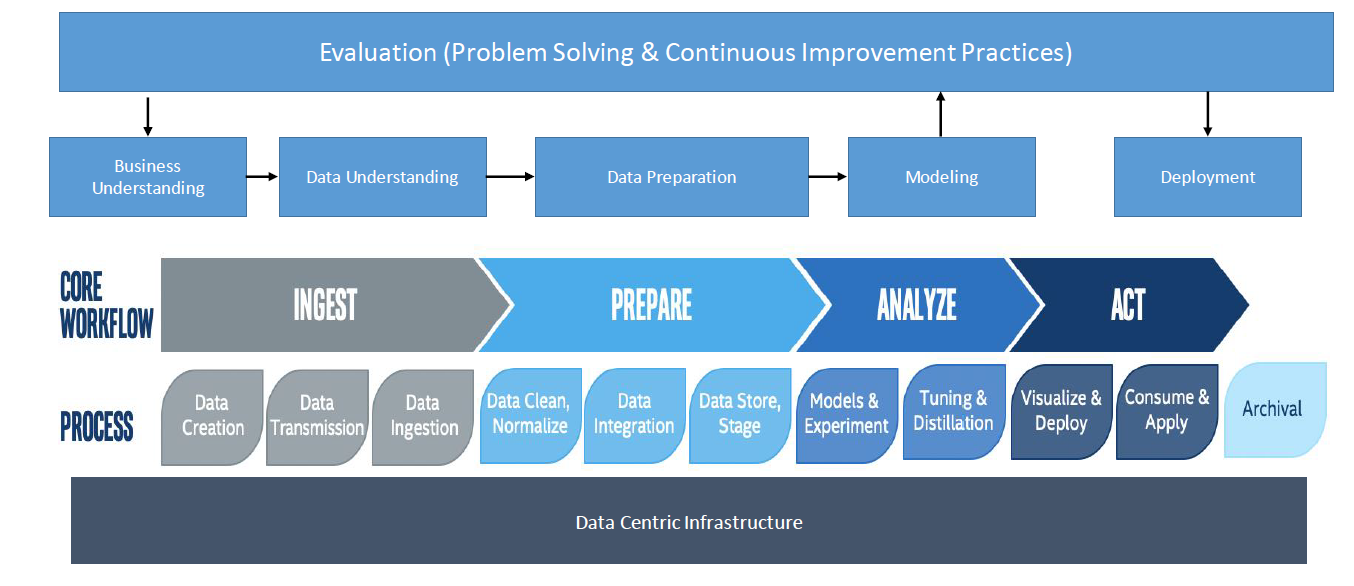
The first thing to think about in this part of the process is the data pipeline. How do we identify what raw data we need, and how do we get it through the pipeline and transform it into insight? There are five key steps in the pipeline: determining the business value of the data, ingesting it, preparing it, analyzing it, and, finally, acting upon the resulting insights.
Let’s look at manufacturing for an example. In determining what data offers business value, you should ask three fundamental questions: What is the demand for my widget? What is the current supply? What is the yield loss? These are seemingly simple questions, but then you have to think about more complex things such as how do I quantify demand, manufacturing capabilities, supply, and yield loss? Where does the data come from? How do I ingest it? How reliable and stable are these data? There are many questions and variables, such as raw product delivery time, projected demand, and unknown yield loss that can create great complexity.
The pipeline simplifies how all of these components come together. Each type of data goes through the key steps in the pipeline, but each will be different. For example, the ingestion of one type of data will vary from the ingestion of another. The idea, though, is to bring all the data together to create a clear picture.
We Have Data! What Do We Do With It?
Depending on the type of data and the questions you are trying to answer, you would use different analytic techniques. For example, in answering how many widgets should be manufactured, you could analyze historical supply and demand through analytics and basic business intelligence. To determine which widgets have visual defects, an algorithm that learns to identify defects in images via deep learning might be the best approach. There is no one technique that solves all problems; each is unique to the problem and the data itself.
Additionally, it’s important to bring in domain experts to help understand the patterns the data yields. The domain expert will understand the data and where it’s coming from, and the data scientist will understand the best approach for the algorithms to gain more insight. If, for example, a decrease in product yield is predicted through a machine learning algorithm, the engineers who need to correct the problem won’t necessarily know where to look without the context of the problem. One of the reasons why organizations aren’t gaining a return on investment to the degree that they should is because they haven’t built their models to be actionable or reflective of the behaviors within the systems they are trying to predict.
How all of this works together comes down to the business questions you are asking and your challenges. For example, you could have an assortment of algorithms telling you how many widgets to manufacture. You might have a deep learning algorithm that recognizes whether a widget has a defect, and even categorizes the defects. But that doesn’t necessarily help if you don’t know why that defect happened. So you have to tie that information to a few more algorithms to obtain correlations to explain the defects, and you need a plan of action to correct the problem.
We Need to Create Insights. How do we Train our Data?
How do we accomplish this? Essentially, you’re bringing all the data together, preparing it, and linking it in order to, for example, quantify supply and predictions in yield loss. You are going to need problem solving and continuous improvement practices over time to meet changing conditions. This is where the culture of the organization comes in. Solving a problem once without a commitment to continuous improvement can cause an organization to miss the real value of doing the analytics in the long run.
We are seeing a major shift today toward organizations with a data-centric infrastructure. Data is no longer just in the data center, but in the cloud, and on the edge. With the business process at the top, leading to continuous improvement, business and data understanding, and all the way to deployment, organizations built on this infrastructure can see a world of difference.