#19 Using Data as a Strategic Asset
Subscribe to get the latest
on Mon Sep 07 2020 17:00:00 GMT-0700 (Pacific Daylight Time)
with Darren W Pulsipher,
In this episode, Darren Pulsipher, Intel Chief Solution Architect, Public Sector, explores how organizations can move from simply hoarding data to using it as a strategic asset.
Keywords
#dataarchitecture #data #datastrategy #people #process
Listen Here
Just like some people hoard things in their homes, afraid to throw anything away, organizations can hoard data. For example, my email folder is 8 gigabytes. I know it does not need to be that big, but I save things in case I might need them. Now multiply that times the number of employees. At Intel, we’ve got a hundred thousand employees. Imagine how much data we’re storing, just in emails, when we do backups. Add in structured and unstructured databases, presentations, spreadsheets, etc…and it’s clear that just storing it all is not a great strategy.
Data Statistics
Let’s look at the statistics that show why this is a bad strategy. Approximately 80 percent of data scientists’ time is spent cleaning up data before they can use it. Less than 50% of structured data is being utilized at all, and less than 1% of unstructured data can be analyzed. So, all of this data is being hoarded, but organizations are not, for the most part, using it. Another issue is who has access to all of this stored data. It is alarming that 70% of employees have access to data that they probably shouldn’t. Just as a hoarder’s piles create fire hazards in the home, unorganized piles of data create security risks in an organization.
Data Explosion
What can we do about this problem? First, we need to understand why there is such an explosion of data. With IOT, everything is connected, and we have data processing happening in a multitude of places. The sheer volume of data that is being generated is incredible. This is exacerbated by regulatory issues; it’s hard to know what we can get rid of and what we can’t. We fill up our storage and then buy more. The technology is basically enabling our data hoarding. We need to look at what we can do differently.
Why We Hoard
Experts say that people hoard because they believe that an item will be useful or valuable in the future, has sentimental value, is unique and irreplaceable, or is too big a bargain to throw away. These same ideas apply to data hoarding. For example, why do I have one of the first presentations I ever gave? It’s stored on a drive and it is in the cloud. I look at it maybe once a year, but I don’t have any real reason beyond sentimental value to keep it. An organization is made up of individuals with these behaviors, and at all different levels of data hoarding, there is fear of getting rid of data.
Becoming Data Centric
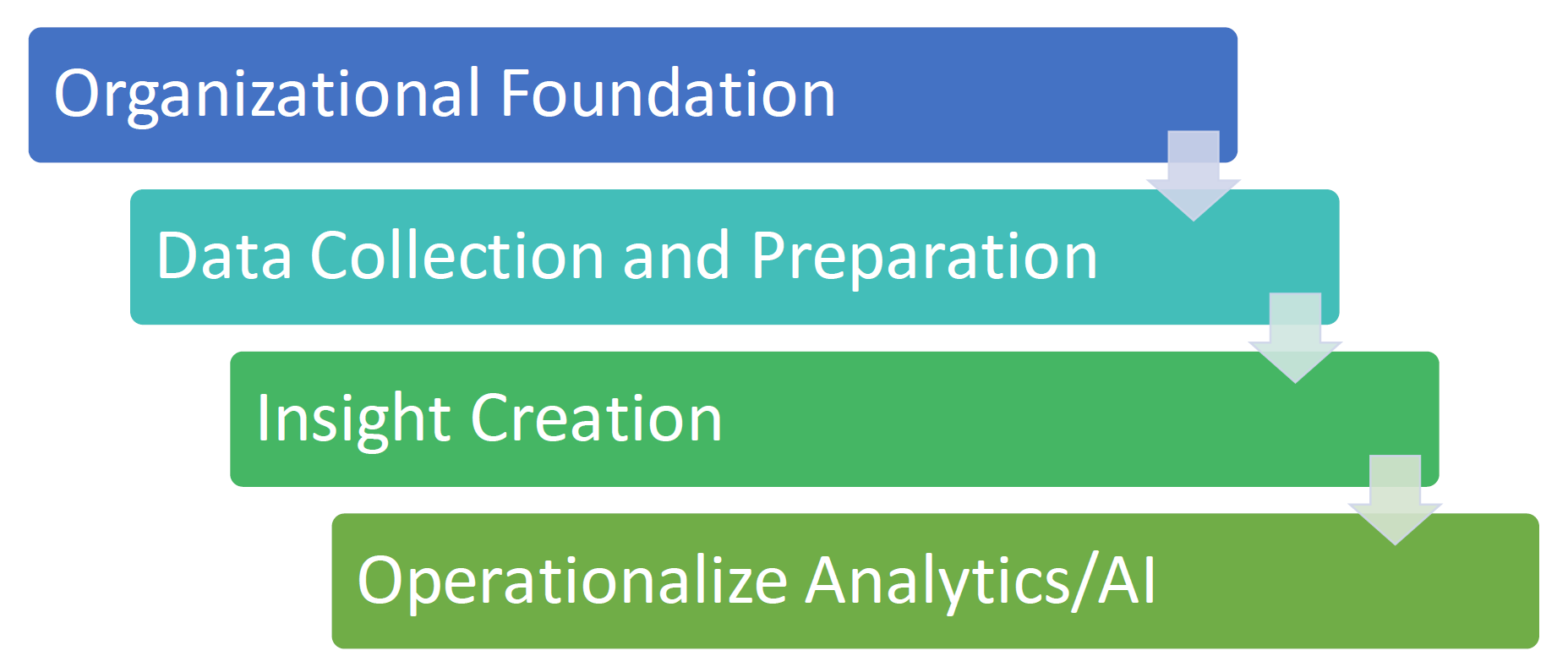
What does it look like to become a data-centric company instead of a storage company? Here is a four-step process to becoming a data-centric organization.
Organizational Foundation
The first step is creating a data-centric organizational foundation. There are four key players with distinctive roles.
Chief Data Officer: The chief data officer’s job is to set strategy and governance over the management of data and the generation of valuable business information. This role is different than that of a chief information officer, who focuses on infrastructure rather than the information itself. This is a difficult job, as the chief data officer is involved in cultural change. They try to keep people from hoarding data, and instead, use it to create real business value.
Data Scientist: Data scientists develop models and blueprints by finding patterns in the data and using predictive analytics. The data scientists’ efforts can become simply a one-time science experiment, however, unless the information is operationalized.
Data Engineer: This is where data engineers come in. They manage data pipelines and operationalize analysis. As new data comes in, new insight is generated without starting over each time.
Data Steward: The data steward manages governance and access to data assets, making sure the right people have the right access at the right time.
With an organization that includes these four roles, the next big question is whether to centralize or distribute operations. For example, perhaps distributed matrix management is already working in your large organization, but a smaller organization may need more rigor and would benefit from a more centralized structure.
Data Collection and Preparation
An article from the Harvard Business Review effectively uses a sports analogy to describe two strategies to catalog data: defense and offense. In defense, the goal is to protect the data. In offense, the goal is to move forward to score as quickly as possible.
Data Defense and Offense
With a defensive strategy, the organization is primarily focused on data security, governance, and compliance. Protecting the data is key. The main data activity will center on extraction, standardization, storage management, and access management. Typically, this strategy will use a more centralized organization and will use a single source of truth.
With an offensive strategy, the organization is primarily focused on moving quickly to improve its competitive position and be as profitable as possible. Data activities will focus on extraction, modeling, visualization, transformation, and enrichment. This strategy will require more flexibility, which means a more distributed organization with multiple versions of truth.
Understanding how to use the data based on the strategy is important. Often, organizations will straddle the fence and it can get confusing. Although every organization needs to be able to play defense and offense, organizations must choose a strategy rather than trying to do both, just as professional-level football players don’t play both sides of the ball.
Analytics Insight
There is an organizational maturity curve to analytics and building insight from your data. The key is to understand where your organization currently resides and what the next steps are to move up the curve.
In the descriptive analytics stage, you are just trying to figure out what is going on. In the diagnostic step, you are figuring out why something happened. In the predictive step, you can predict what will happen in the future based on historical data. This is where many organizations strive to be, but the first two steps must be accomplished first. Above predictive is prescriptive, where you can understand why something will happen and guide the organization according to expectations. At the top of the steps is analytic insight, or foresight, where you are making things happen, even progressing beyond prescription.
One reason it is important to understand where your organization currently sits is because there are specific tools for each phase. For example, you don’t want to be stuck with an AI project that is using prescriptive, or even predictive, algorithms when your organization is still on the descriptive step.
Operationalize It
To achieve the goal of operationalization, or making a repeatable process, there are three key elements: a data-centric infrastructure, data pipelines, and business flow. The data-centric infrastructure allows you to know where all your data is and what’s in that data through various tools such as a metadata manager like elastic search or meta-data catalogs and repositories. Data pipelines have great tools to enable the process from ingestion to analysis to action. A defensive or offensive strategy will determine which tools you will use in your pipeline. The last element, business flow, is where business understanding of your data and processes will allow deployment of a continuous improvement process to ensure repeatable, valuable insights.
Call to Action
First, develop a data strategy. Get organized and figure out where all of your data is and catalog it. Decide on a defensive or offensive strategy, and then take your analysis insight steps one at a time, using the right tools. Most importantly, operationalize your insights to get the best business value.