#25 Operazionalizzare i flussi di dati
Subscribe to get the latest
on 2020-10-14 00:00:00 +0000
with Darren W Pulsipher, Sarah Kalicin,
Darren Pulsipher, Chief Solutions Architect, Pubblico Settore, Intel, parla con Sarah Kalicin, Lead Data Scientist, Intel, sulla operazionalizzazione del data pipeline dell'organizzazione. È necessario un lavoro di squadra per modellare, monitorare e produrre una continua fonte di informazioni preziose. Questo è l'episodio finale della serie Kick-starting your Organizational Transformation to Become Data-Centric.
Keywords
#deeplearning #automation #collaboration #multicloud
Per l’ultimo episodio di questa serie, Darren parla con Sarah Kalicin, Lead Data Scientist presso Intel, riguardo all’operazionalizzazione del tuo flusso di dati. Discutono di come, una volta ottenute le tue informazioni sui dati, puoi trasformarle da un esperimento scientifico a tempo determinato in una fonte continua di informazioni.
Come operazionalizziamo le intuizioni analitiche?
La prima cosa da comprendere riguardo al data pipeline è che non è come un sistema elettrico chiuso che puoi installare, dimenticare e sei mesi dopo premere un interruttore sapendo che la lampadina si accenderà. Un data pipeline è diverso perché i dati sono variabili; possono cambiare o degradare, ad esempio, quindi non sarai necessariamente ricompensato con l’accensione della lampadina in nessun momento, o in questo caso, l’approfondimento che stai cercando. Devi sempre pensare a ciò che può andare storto nel sistema e come correggere questi cortocircuiti.
Rilevare anomalie è parte integrante del processo. Non si può pianificare tutto, ma almeno è necessario essere in grado di riconoscere quando qualcosa è accaduto al di fuori dei limiti delle analisi originali. Un esempio è la crisi del COVID, un evento imprevedibile che ha causato schemi molto diversi dalla norma per molti sistemi. Un altro esempio potrebbe essere un’azienda produttrice di widget. Per sapere quanti widget produrre, il flusso di dati contiene la domanda dei clienti, la fornitura attuale e la perdita di rendimento. Questi dati potrebbero essere abbastanza stabili nel tempo, ma potrebbe verificarsi, ad esempio, un evento di pubbliche relazioni che provoca un’esplosione della domanda dei clienti. Questo potrebbe influire notevolmente sui modelli. L’apprendimento automatico e l’apprendimento profondo osservano schemi familiari e, se non hanno mai visto questi schemi prima, i modelli avranno problemi o si degraderanno. Bisogna rimanere sull’orlo della scoperta.
L’unico modo per restare al passo con le scoperte è automatizzare le tue condotte di dati per un accesso tempestivo alle informazioni. Questo è il vantaggio competitivo: dati aggiornati e illuminanti che possono aiutarti a risolvere rapidamente le tue domande.
Le squadre IT e le squadre di dati devono collaborare sull’automazione e determinare cosa deve essere automatizzato per i dati in arrivo e sulla gestione di eventuali modifiche al modello che gli scienziati dei dati desiderano apportare in modo che possa essere facilmente integrato nel flusso di lavoro.
Dispiego brevi circuiti
Ci sono due tipi di controlli che possono prevenire i cortocircuiti nella distribuzione: i controlli del sistema analitico e i controlli organizzativi.
Il controllo del sistema analitico si tratta di mettere in funzione i modelli che hai addestrato, alimentando i dati per rispondere facilmente alle tue domande. Questi modelli implementati devono essere moderati per verificare l’accuratezza dei dati. Molte cose possono causare un impatto negativo sui dati, come i cambiamenti ambientali, la calibrazione delle macchine, problemi di distribuzione e così via.
Ciò non è così diverso dal mondo dello sviluppo software in cui i cambiamenti possono influenzare le previsioni. Il dipartimento IT è familiare con il processo di esecuzione dei test per assicurarsi che i loro modelli o applicazioni funzionino secondo le linee guida stabilite, quindi i dev ops e gli scienziati dei dati dovrebbero approfittare di queste risorse e conoscenze. Non c’è bisogno di inventare nuovi processi, ma invece, i gruppi dovrebbero unire le risorse per prepararsi al successo.
I controlli organizzativi risalgono a una fondazione organizzativa che si impegna ad essere centrata sui dati e a fornire le persone e le risorse corrette per lavorare insieme verso obiettivi comuni. La migliore possibilità per ottenere l’operazionalizzazione si verifica quando c’è collaborazione, fiducia, comprensione delle esigenze e loop di feedback tra i gruppi all’interno dell’organizzazione.
I cicli di feedback sono fondamentali in questo processo. Ad esempio, gli specialisti della materia possono fornire informazioni sulle dinamiche di mercato in modo che gli scienziati dei dati possano monitorare il modello per queste variazioni nei dati. Se un modello verrà utilizzato nel tempo, avrà sempre bisogno di essere iterato e migliorato costantemente.
I consumatori dei dati dovrebbero avere un cruscotto che fornisce loro informazioni e consente loro di approfondire il motivo per cui qualcosa sembra un po’ strano. Più possono indagare o sollevare ciò che deve essere indagato, più la vostra organizzazione si sentirà autonoma.
Pipeline
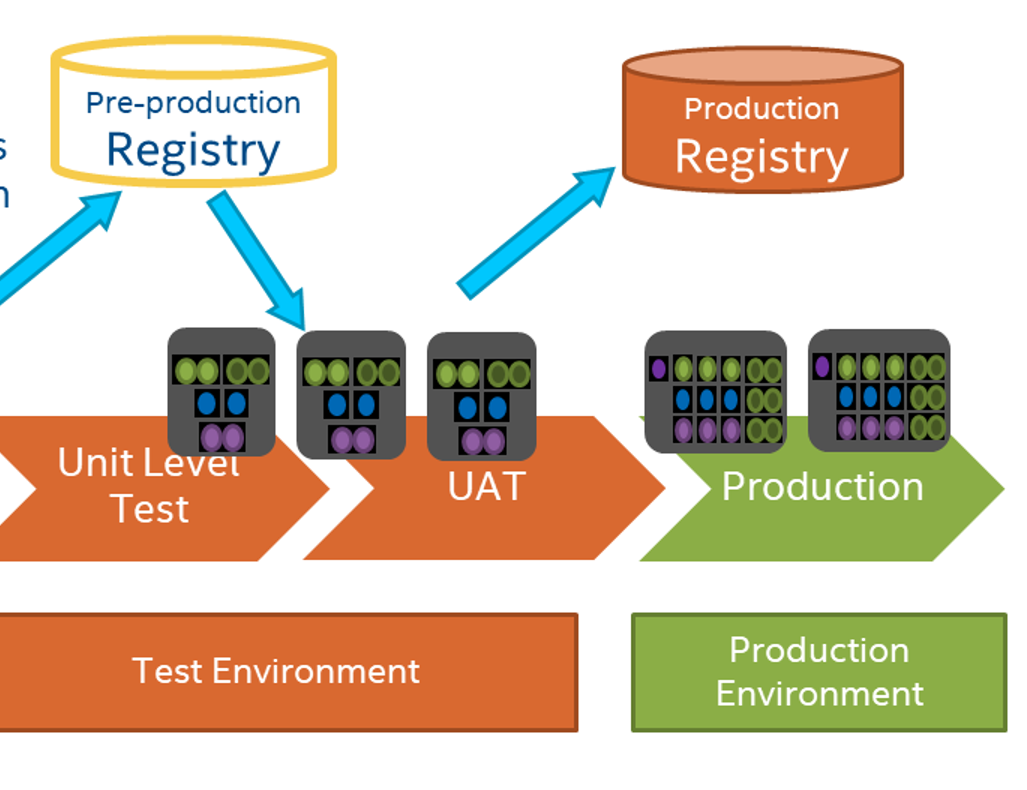
Una chiave dal lato IT per operazionalizzare la pipeline dei dati è utilizzare un controllo delle versioni come GitHub, in modo da poter avere accesso alle versioni precedenti del tuo modello. Per scopi di controllo, è altrettanto importante poter archiviare i dati che hanno creato il modello e altri dati storici. Si desidera essere in grado di osservare i pattern e vedere come una determinata caratteristica è cambiata o ha influenzato il modello. È anche possibile inserire dati storici nei nuovi modelli per vedere quanto influiscono sui dati attuali.
Ad esempio, alcuni sistemi avranno una visione distorta con un numero elevato di persone che lavorano da casa durante la pandemia di COVID-19. Un esempio è la Marina. Da quando è iniziata la pandemia, il 95% dei loro dipendenti IT lavora da remoto e la loro produttività è aumentata del 35%. Da questo singolo dato, potremmo dire che tutti lavoreranno da casa da ora in poi. Riuscirai a mantenere un aumento del 35% o, se le persone torneranno in ufficio, vedrai una diminuzione del 35%? Ovviamente, questo singolo dato non è necessariamente sufficiente per prevedere la produttività effettiva.
Un altro strumento che l’IT può offrire è l’integrazione e il deployment continui. Utilizzando Jenkins o GitHub Actions o un tool simile durante il lavoro su un modello, è possibile eseguire automaticamente test sul modello con i propri dati o generare dati di prova al volo.
Le persone di IT e gli scienziati dei dati devono collaborare su cosa e come monitorare l’output dei modelli. IT può monitorare l’output automaticamente e possono anche monitorare le prestazioni dei modelli nell’infrastruttura. Un esempio è che IT, con la distribuzione automatizzata di integrazione continua, può avvertire rapidamente gli scienziati dei dati quando un modello richiede più tempo del normale per evitare che sfugga al controllo. Se IT è interessato alla creazione di valore dei dati, che è generalmente mancante nell’intero settore, il processo sarà più facile e coerente per tutti.
Un altro aspetto da considerare è il disegno degli esperimenti, poiché le interazioni tra variabili e caratteristiche sono altrettanto importanti. Gli esperti del settore possono aiutare a determinare quali sono le potenziali interazioni, e tu puoi modellarle per comprendere quale variabilità ci si può aspettare.
È emozionante che un data scientist possa prendere materiale grezzo e trasformarlo in conoscenza. Tuttavia, richiede un team. Più tutti nell’organizzazione possono imparare gli uni dagli altri in un ambiente di squadra, più cose straordinarie possono accadere.