#41 L'Arte Nera del DevOps
Subscribe to get the latest
on 2021-03-10 00:00:00 +0000
with Darren W Pulsipher,
Darren Pulsipher, Chief Solution Architect, Public Sector, Intel, definisce i termini comuni di DevOps e spiega dove si inserisce DevOps nella tua organizzazione.
Keywords
#devsecops #devops #automation #advancedcommunications #multicloud #process #technology #policy
Diamo uno sguardo a dove si inserisce DevOps nella tua infrastruttura.
In fondo a una pila normale, abbiamo uno strato fisico che potrebbe rappresentare una nuvola, un centro dati, dispositivi IoT o infrastrutture tradizionali.
Inoltre, di solito c’è un’infrastruttura definita dal software che astrae la complessità nella gestione dei singoli componenti hardware.
Il prossimo passo è un livello di gestione del servizio, che include l’ecosistema di virtualizzazione dei contenitori e un livello di gestione delle informazioni distribuito, che comprende il piano dati, i laghi dati e tutto ciò che gestisce i tuoi dati.
Poi arriva il livello dell’applicazione. Gli sviluppatori di applicazioni utilizzano i servizi all’interno dei livelli dell’applicazione. Proprio all’interfaccia tra il livello dell’applicazione e il piano di gestione dei dati e della gestione dei servizi si trovano gli strumenti SecDevOps o DevOps. Questi strumenti includono aspetti di sicurezza e identità che garantiscono un modo sicuro di integrare e distribuire continuamente i tuoi prodotti.
Applicazione / Livello di carico di lavoro
In cima alla piattaforma dell’applicazione e al livello del carico di lavoro che alimenta il SecDevOps, ci sono tre tipi di carichi di lavoro: carichi di lavoro basati sugli eventi, carichi di lavoro procedurale e un ibrido dei due, che sono carichi di lavoro basati su GUI o UI.
Un semplice esempio di un carico di lavoro orientato agli eventi sarebbe quando un ordine di acquisto arriva nel tuo sistema causando l’attivazione di altre azioni. Ci possono essere passaggi sequenziali o paralleli, interazione con gli esseri umani e automazione e interazione con diverse applicazioni o sottosistemi all’interno dell’azienda.
Molti strumenti per l’automazione del carico di lavoro sono disponibili. Alcuni sono basati su script e altri utilizzano l’automazione dei processi robotici, che sono più orientati all’interfaccia grafica (GUI) o all’interfaccia utente (UI). Questi strumenti lavorano sull’automazione dei servizi sottostanti, quindi i carichi di lavoro guidano l’interazione del servizio.
I servizi tradizionalmente si suddividono in tre categorie principali: applicazioni, come prodotti già pronti come Word o un’applicazione SAP; servizi complessi, che vengono sviluppati per uno scopo specifico, come uno stack MEAN con Mongo; e servizi semplici, che fanno una cosa sola, ad esempio MongoDB che archivia il database.
C’è una nuova categoria a causa della crescita dell’IA e dell’Apprendimento Automatico. Molti servizi non fanno molto senza un modello ad esso associato, quindi abbiamo aggiunto modelli di intelligenza artificiale al livello del servizio, che trattiamo allo stesso modo di un servizio semplice.
Giornata del Developer nella vita
Dopo aver compreso i carichi di lavoro e i servizi, possiamo analizzare cosa fa tipicamente uno sviluppatore.
Uno sviluppatore scriverà qualche codice sulla propria postazione di lavoro e eseguirà alcuni test di funzionalità. Successivamente, effettuerà il commit del codice su GitHub, ad esempio, e verrà avviato un processo di integrazione continua e consegna continua (CICD). Esso eseguirà controlli di sicurezza sul codice, come ad esempio linter, analisi statica e analisi dinamica.
Una volta superati questi test, di solito verrà controllato in un ramo di integrazione in cui altre persone del team di sviluppo prenderanno i dati, li svilupperanno e integreranno il loro codice con quello dello sviluppatore. Successivamente, una volta superati i loro test, verrà spinto in una fase di test. Una volta superata questa fase, verrà messo in produzione.
Questo è un tipico pipeline CICD, che esiste da decenni. Nel corso degli anni, i diversi modi di descrivere le pipeline sono stati consolidati e standardizzati, limitando complessità ed errori.
Stack di DevSecOps
Il pipeline è solo un elemento di un insieme SecDevOps.
Altri elementi necessari includono un registro e un repository. Pensate a questi come repository versionati per conservare gli artefatti che vengono generati durante il CICD pipeline, in modo che siano facilmente disponibili per essere riutilizzati più volte.
Un altro elemento importante è un framework di automazione. Questo aiuta a alleviare il lavoro umano nell’esecuzione di compiti come controlli di sicurezza o promozione delle versioni da una fase all’altra. Gli strumenti per l’automazione sono maturi e la formazione è disponibile, quindi un buon framework di automazione dovrebbe essere fondamentale.
Anche se la gestione dell’ambiente spesso cresce organicamente nel tempo, ha senso gestire e progettare gli ambienti in modo appropriato per ottenere maggiore affidabilità e ripetibilità.
Un elemento chiave al di sotto di tutto è un profilo di sicurezza. Dovresti essere in grado di avere la capacità di definire profili di sicurezza, in modo che possano essere utilizzati in più ambienti e su stack di applicazioni multipli.
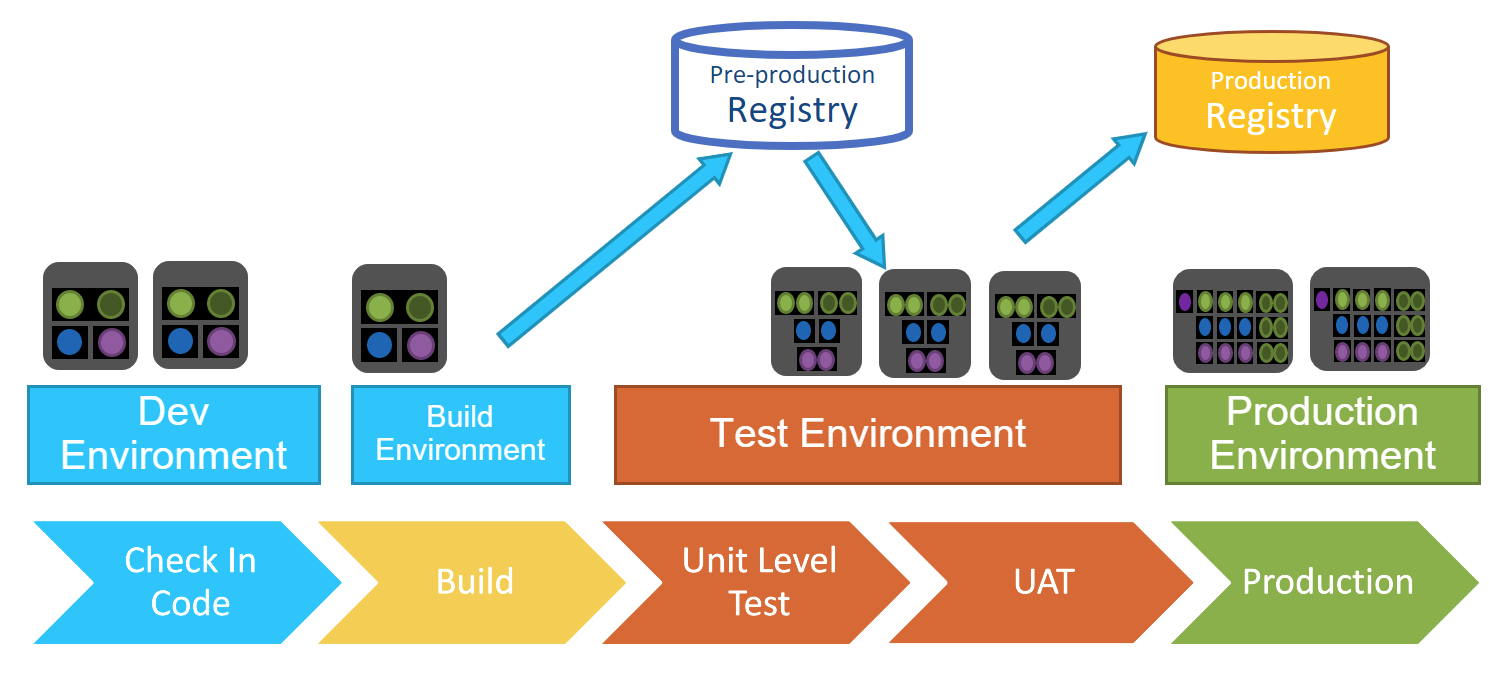
Registri / Repository
Di solito ci sono almeno due tipi di repository differenti. Il primo è un repository di staging, dove puoi generare immagini (una raccolta di tutto il codice necessario per avviare un contenitore, ad esempio) e archiviare cose come identità e chiavi segrete. Questo repository contiene tutto ciò di cui hai bisogno per trasferire le cose in produzione. Alcune organizzazioni possono avere più repository di staging in quanto gli elementi diversi passano attraverso diverse fasi di maturità fino a raggiungere il repository di produzione. Vuoi essere in grado di tornare alle versioni precedenti se necessario.
Nella repository di produzione, o in oro, le immagini vengono bloccate, rendendole autenticate e criptate. Solo le cose presenti nella repository in oro vengono spostate nella produzione.
Fasi
Il modo migliore per pensare alle fasi nel pipeline CICD è che ogni fase funzioni in un singolo ambiente. Ad esempio, in una fase di compilazione, esiste un ambiente di compilazione autonomo con politiche. Solo quando tutti i passaggi in questa fase sono completati, le cose possono passare alla fase successiva. Ciò evita di consumare risorse con compilazioni parallele ed esecuzioni che possono alla fine fallire. Allo stesso tempo, è meglio non avere così tante fasi che ostacolino il progresso, quindi è importante avere un piano definito e accurato.
Passi
All’interno delle fasi ci sono dei passaggi in cui il lavoro viene effettivamente svolto. Nella costruzione e nel testing del software, i passaggi possono essere eseguiti in parallelo o in sequenza; ci sono molti strumenti che consentono di definire queste operazioni. Sebbene alcuni abbiano un’interfaccia grafica per questo, la maggior parte degli sviluppatori preferisce un formato testuale perché consente il controllo delle versioni della pipeline e dei passaggi, consentendo controlli di sicurezza sulla pipeline.
Pipeline
Con fasi e passaggi definiti, si ha una vera pipeline. Invece di definire una pipeline unica per tutte le tue applicazioni, cosa che di solito fallisce perché diventa eccessivamente complessa con molte condizioni o troppo restrittiva, ti consiglio di utilizzare pipeline di template e modificarle se necessario, assicurandoti che rispettino gli standard di conformità e le normative. È importante stabilire una pipeline adeguata all’inizio di un progetto, così come la flessibilità durante lo sviluppo del progetto.
Ambienti
Invece di creare ambienti ad hoc, è meglio crearli con intenzione fin dall’inizio. DevOps o SecDevOps possono integrare politiche di sicurezza e conformità in tutti i diversi progetti, garantendo la sicurezza.
Service Stack in Italian is “stack di servizi”.
Diamo uno sguardo a come lavorano i programmatori, che riguarda i servizi al giorno d’oggi. Anche se i programmatori lavorano in un’applicazione monolitica, tendono a raggruppare il loro lavoro in unità funzionali come database, nodi di logica di business o strati di trasporto. Ad esempio, utilizzando un semplice servizio come MongoDB. Quando un programmatore avvia quel contenitore sul proprio laptop, gli offre la funzionalità che si aspetta di memorizzare i dati in un modo non SQL in un documento. Sul laptop, potrebbe essere l’unico contenitore in esecuzione.
In un ambiente di prova o sviluppo, potrebbero esserci più istanze di quel servizio in esecuzione e lo sviluppatore potrebbe distribuire un cluster di MongoDB services e collegarli insieme per un test. Il servizio rimane comunque un servizio Mongo DB, ma il suo comportamento cambia in base all’ambiente in cui si trova. L’obiettivo per gli sviluppatori è scrivere codice e effettuare il controllo su di esso rispetto al servizio MongoDB sui loro laptop per garantire che funzioni correttamente in produzione.
Un servizio semplice come MongoDB è necessario, ma di per sé non molto utile. Servizi complessi come le pile LAMP o MEAN sono più importanti. Questi sono diversi servizi che funzionano insieme, agendo essenzialmente come un unico servizio. Riuniti insieme, questo permette di implementare un servizio complesso su un laptop e ci sono due o tre contenitori di servizi semplici che sono in esecuzione, offrendo agli sviluppatori la funzionalità necessaria per verificare il loro codice.
Una volta che il codice viene verificato, inizia il processo di sviluppo in cui il programmatore si integra con altre persone. Lo stesso servizio complesso può adottare un modo completamente diverso di fare le cose. A quel servizio complesso possono essere collegate molte politiche di sicurezza per garantirne la sicurezza, l’affidabilità e la resilienza.
Definizioni di Servizio/Applicazione
È importante capire i concetti di servizi semplici e complessi perché gli sviluppatori di software devono definire come farli funzionare. Ci sono alcune definizioni. Una viene chiamata definizione dell’immagine. Queste sono spesso nel mondo dei container, chiamate immagini Docker. Il file Docker definisce ciò che c’è in quell’immagine. Questo è considerato un semplice contenitore di per sé, anche se le persone stanno iniziando a usare i container per cose complesse.
All’interno delle definizioni di servizio, possiamo includere multiple definizioni di immagine, ad esempio, Docker Compose, Kubernetes Operators, Helm Charts, Terraform e perfino CNAB. Questi sono strumenti che ti permettono di definire un servizio. Un servizio è più di un semplice contenitore; è l’ambiente in cui viene eseguito il contenitore. Potrebbe includere definizioni di rete, connettività dei volumi o persino politiche di distribuzione. Una “definizione di servizio” completa ha definizioni di immagine, configurazione e provisioning.
Mettere tutto insieme
Quando uno sviluppatore sta creando un nuovo servizio, non sta solo sviluppando il codice per l’immagine; sta anche definendo l’ambiente, o la configurazione, in cui deve essere eseguito. È qui che possono convergere la trama del tuo ambiente e la definizione del servizio. Durante l’esecuzione, produrrà l’ambiente necessario affinché il contenitore possa essere eseguito in modo efficace in modo ripetibile, in modo da poter spostare facilmente il codice dall’esecuzione su un desktop all’esecuzione nella produzione completa il più rapidamente possibile.