#41 El Arte Negro de DevOps
Subscribe to get the latest
on 2021-03-10 00:00:00 +0000
with Darren W Pulsipher,
Darren Pulsipher, Arquitecto Principal de Soluciones, Sector Público, Intel, define los términos comunes de DevOps y explica dónde encaja DevOps en tu organización.
Keywords
#devsecops #devops #automation #advancedcommunications #multicloud #process #technology #policy
Echemos un vistazo a dónde encaja DevOps en tu infraestructura.
En la parte inferior de una pila normal, tenemos una capa física que puede significar una nube, un centro de datos, dispositivos de IoT o una infraestructura heredada.
Además de eso, normalmente hay una infraestructura definida por software que abstrae la complejidad de gestionar las piezas individuales de hardware.
A continuación se encuentra una capa de gestión de servicios, que incluye la virtualización del ecosistema de contenedores, y una capa de gestión de información distribuida, que incluye el plano de datos, los depósitos de datos y todo lo relacionado con la gestión de sus datos.
A continuación viene la capa de aplicación. Los desarrolladores de aplicaciones utilizan los servicios dentro de las capas de aplicación. Justo en la interfaz entre la capa de aplicación y el plano de gestión de datos y el manejo de servicios se encuentran las herramientas de SecDevOps o DevOps. Estas herramientas incluyen aspectos de seguridad e identidad que brindan una forma segura de integrar y desplegar continuamente sus productos.
Capa de aplicación / carga de trabajo
En la parte superior de la capa de aplicación y carga de trabajo que alimenta a SecDevOps, hay tres tipos de cargas de trabajo: cargas de trabajo impulsadas por eventos, cargas de trabajo procedimentales y una combinación de ambas, que son cargas de trabajo impulsadas por GUI o UI.
Un ejemplo simple de una carga de trabajo orientada a eventos sería cuando una orden de compra llega a su sistema, causando que se realicen otras acciones. Pueden haber pasos secuenciales o paralelos, interacciones con humanos, automatización e interacción con varias aplicaciones o subsistemas diferentes dentro de la empresa.
Muchas herramientas de automatización de carga de trabajo están disponibles. Algunas están creadas con guiones y otras utilizan la automatización de procesos robóticos, que son más basadas en GUI y UI. Estas herramientas trabajan en la automatización de servicios subyacentes, de modo que las cargas de trabajo dirigen la interacción de servicios.
Los servicios tradicionalmente se dividen en tres categorías principales: aplicaciones, como productos listos para usar como Word o una aplicación SAP; servicios complejos, construidos para un propósito específico, como una pila MEAN con Mongo; y servicios simples, que hacen una sola cosa, por ejemplo MongoDB, que almacena la base de datos.
Hay una nueva categoría debido al crecimiento de la IA y el ML. Muchos servicios no hacen mucho sin un modelo adjunto, por lo tanto, hemos añadido modelos de IA a la capa de servicio, los cuales tratamos de manera similar a un servicio simple.
Día del Desarrollador en la vida.
Después de comprender las cargas de trabajo y los servicios, podemos analizar lo que normalmente hace un desarrollador.
Un desarrollador escribirá algún código en su estación de trabajo y ejecutará algunas pruebas de funcionalidad. Luego, verifica el código en GitHub, por ejemplo, y se inicia un flujo continuo de integración y entrega continuas (CICD). Se ejecutan controles de seguridad en el código, como linter, análisis estático y análisis dinámico.
Una vez que haya pasado esas pruebas, generalmente se verificará en una rama de integración donde otras personas del equipo de desarrollo toman los datos, los desarrollan e integran su código con el código del desarrollador. Luego, una vez que haya pasado sus pruebas, se implementará en una etapa de prueba. Una vez que haya pasado esa etapa, pasará a producción.
Este es un típico pipeline de CI/CD, que ha existido durante décadas. Con el paso de los años, las diferentes formas de describir los pipelines se han consolidado y estandarizado, limitando complejidades y errores.
Pila de DevSecOps
El canal de comunicación es solo un elemento de una pila SecDevOps.
Otros elementos necesarios incluyen un registro y un repositorio. Piense en ellos como repositorios versionados para mantener artefactos que se generan durante el pipeline de CICD, de manera que estén fácilmente disponibles para ser utilizados una y otra vez.
Otro elemento importante es un marco de automatización. Esto ayuda a aliviar el trabajo humano de ejecutar tareas como controles de seguridad o promover construcciones de una etapa a otra. Las herramientas de automatización son maduras y hay disponibilidad de capacitación, por lo que un buen marco de automatización debería ser fundamental.
Aunque la gestión del entorno a menudo crece de forma orgánica con el tiempo, tiene sentido administrar y diseñar los entornos de manera adecuada para obtener mayor confiabilidad y repetibilidad.
Un elemento clave en todo esto es un perfil de seguridad. Debes tener la capacidad de definir perfiles de seguridad, para que puedan ser utilizados en múltiples entornos y en varias aplicaciones.
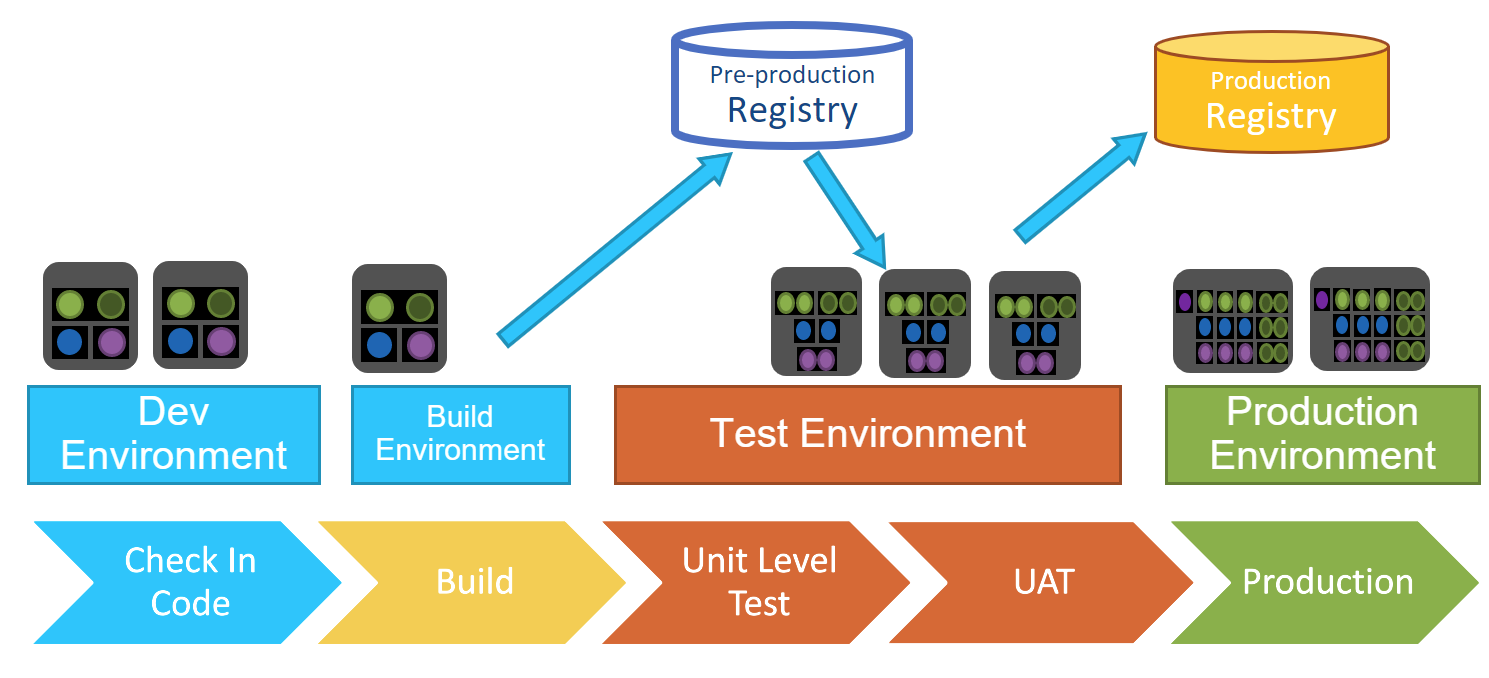
Registros / Repositorios
Normalmente hay al menos dos tipos diferentes de repositorios. El primero es un repositorio de preparación, donde se pueden generar imágenes (una recopilación de todo el código necesario para iniciar un contenedor, por ejemplo) y almacenar cosas como claves de identidad y secretos. Este repositorio contiene todo lo necesario para llevar las cosas a producción. Algunas organizaciones pueden tener varios repositorios de preparación a medida que los diferentes elementos pasan por diferentes etapas de madurez hasta llegar al repositorio de producción. Es importante poder retroceder a versiones anteriores si es necesario.
En el repositorio de producción, o dorado, las imágenes se bloquean, notarizan y cifran. Solo las cosas en el repositorio dorado se mueven a la producción.
Etapa or Fases
La mejor manera de pensar en las etapas del pipeline de CICD es que cada etapa funciona en un solo ambiente. Por ejemplo, en una etapa de construcción, hay un entorno de construcción contenido con políticas. Solo cuando se completan todos los pasos en esta etapa, las cosas pueden pasar a la siguiente etapa. Esto evita el consumo excesivo de recursos con construcciones paralelas y ejecuciones que eventualmente pueden fallar. Al mismo tiempo, es mejor no tener demasiadas etapas que obstaculicen el progreso, por lo que es importante tener un plan definido y cuidadoso.
Pasos
Dentro de las etapas se encuentran los pasos donde el trabajo realmente se lleva a cabo. Al construir y probar software, los pasos pueden ejecutarse en paralelo o en secuencia; existen muchas herramientas que permiten definir estas operaciones. Aunque algunos tienen una interfaz gráfica para esto, la mayoría de los desarrolladores prefieren un formato de texto porque permite el control de versiones del flujo de trabajo y los pasos, lo que permite realizar controles de seguridad contra el flujo de trabajo.
Tubería
Con etapas y pasos definidos, tienes un pipeline real. En lugar de definir un pipeline único para todas tus aplicaciones, lo cual suele fallar porque se vuelve excesivamente complejo con muchas condiciones o demasiado restrictivo, recomiendo utilizar plantillas de pipelines y modificarlas según sea necesario, asegurándose de que cumplan con los estándares de cumplimiento y regulaciones. Es importante establecer un pipeline adecuado al comienzo de un proyecto, al igual que mantener la flexibilidad a medida que el proyecto avanza.
Entornos
En lugar de crear entornos improvisados, es mejor crearlos con intención desde el principio. DevOps o SecDevOps pueden implementar políticas de seguridad y cumplimiento en todos los proyectos diferentes, garantizando la seguridad.
Service Stack would be translated to “Pila de Servicios” in Spanish.
Echemos un vistazo a cómo trabajan los desarrolladores, lo cual es en servicios hoy en día. Incluso si los desarrolladores están trabajando en una aplicación monolítica, tienden a agrupar su trabajo en unidades funcionales como bases de datos, nodos de lógica de negocio o capas de transporte. Por ejemplo, utilizando un servicio sencillo como MongoDB. Cuando un desarrollador ejecuta ese contenedor en su laptop, le brinda la funcionalidad que espera para almacenar datos de una manera no SQL en un documento. En la laptop, puede ser el único contenedor en ejecución.
En un entorno de prueba o desarrollo, puede haber varias instancias de ese servicio en ejecución, y el desarrollador puede implementar un grupo de servicios de MongoDB y conectarlos entre sí para realizar una prueba. El servicio sigue siendo un servicio de MongoDB, pero su comportamiento cambia según el entorno en el que se encuentre. El objetivo de los desarrolladores es escribir código y verificarlo contra el servicio de MongoDB en sus computadoras portátiles para garantizar que se ejecutará correctamente en producción.
Un servicio simple como MongoDB es necesario, pero por sí solo no es muy útil. Los servicios complejos como las pilas LAMP o las pilas MEAN son más importantes. Estos son múltiples servicios que se ejecutan juntos, actuando básicamente como un solo servicio. Al agruparlos juntos, esto despliega un servicio complejo en un dispositivo portátil y hay dos o tres contenedores de servicios simples que se están ejecutando, proporcionando a los desarrolladores la funcionalidad necesaria para hacer check-in de su código.
Una vez que el código se ha verificado, comienza en el canal de desarrollo donde el desarrollador se integra con otras personas. El mismo servicio complejo puede adoptar una forma completamente diferente de hacer las cosas. Se pueden adjuntar muchas políticas de seguridad a ese servicio complejo para asegurarse de que sea seguro, confiable y resistente.
Definiciones de Servicio/Aplicación
Es importante entender los conceptos de servicios simples y complejos porque los desarrolladores de software deben definir cómo hacer que funcionen. Hay algunas definiciones. Una se llama definición de imagen. Estas se encuentran frecuentemente en el mundo de los contenedores, llamadas imágenes de Docker. El archivo Docker define lo que hay en esa imagen. Esto se considera un contenedor simple por sí mismo, aunque las personas están empezando a utilizar contenedores para cosas más complejas.
Dentro de las definiciones de servicio, podemos incluir múltiples definiciones de imágenes, por ejemplo, Docker Compose, operadores de Kubernetes, Helm Charts, Terraform e incluso CNAB. Estas son herramientas que te permiten definir un servicio. Un servicio es más que solo el contenedor; es el entorno en el que se ejecuta el contenedor. Puede incluir definiciones de red, conectividad de volumen o incluso políticas de implementación. Una “definición completa de servicio” tiene definiciones de imágenes, configuración y aprovisionamiento.
Juntándolo todo
Cuando un desarrollador está creando un nuevo servicio, no solo está desarrollando el código para la imagen; también está definiendo el entorno o configuración en el que debe ejecutarse. Aquí es donde se puede unir la malla de tu entorno y la definición del servicio. En tiempo de ejecución, se producirá el ambiente que se necesita para que el contenedor se ejecute de manera efectiva de manera repetible, de modo que puedas mover fácilmente el código desde un escritorio a una producción completa lo más rápido posible.