#41 Die Schwarze Kunst von DevOps
Subscribe to get the latest
on 2021-03-10 00:00:00 +0000
with Darren W Pulsipher,
Darren Pulsipher, Chef Solution Architect im öffentlichen Sektor bei Intel, definiert gängige DevOps-Begriffe und erklärt, wo DevOps in Ihrer Organisation angesiedelt ist.
Keywords
#devsecops #devops #automation #advancedcommunications #multicloud #process #technology #policy
Lass uns einen Blick darauf werfen, wo DevOps in deine Infrastruktur passt.
Am unteren Ende einer normalen Stapelung haben wir eine physische Schicht, die eine Cloud, ein Rechenzentrum, IoT-Geräte oder vorhandene Infrastruktur bedeuten kann.
Darüber hinaus gibt es normalerweise eine softwaredefinierte Infrastruktur, die die Komplexität der Verwaltung der einzelnen Hardwarekomponenten abstrahiert.
Als Nächstes folgt eine Service-Management-Schicht, die die Virtualisierung des Container-Ökosystems und eine verteilte Informationsmanagement-Schicht umfasst. Diese beinhaltet die Datenebene, Datenseen und alles, was Ihre Daten verwaltet.
Dann kommt die Anwendungsebene. Anwendungsentwickler nutzen die Dienste innerhalb der Anwendungsebenen. Direkt an der Schnittstelle zwischen der Anwendungsebene und der Datenspeicherungsebene sowie dem Dienstmanagement befinden sich das SecDevOps- oder DevOps-Toolkit. Diese Tools umfassen Sicherheits- und Identitätsaspekte, die eine sichere Möglichkeit für die kontinuierliche Integration und Bereitstellung Ihrer Produkte bieten.
Anwendungsschicht / Arbeitslastschicht
An der Spitze der Anwendungs- und Arbeitslastschicht, die SecDevOps speist, gibt es drei Arten von Arbeitslasten: ereignisgesteuerte Arbeitslasten, prozedurale Arbeitslasten und eine Mischung aus beiden, die GUI- oder UI-gesteuerte Arbeitslasten sind.
Ein einfaches Beispiel für eine ereignisgesteuerte Arbeitsbelastung wäre, dass eine Bestellung in Ihrem System eingeht und andere Dinge ausgelöst werden. Es können sich sequenzielle oder parallele Schritte ergeben, Interaktion mit Menschen sowie Automatisierung und Interaktion mit verschiedenen Anwendungen oder Teilsystemen innerhalb des Unternehmens.
Viele Workload-Automatisierungstools stehen zur Verfügung. Einige davon sind skriptbasiert, während andere die robotergesteuerte Prozessautomatisierung verwenden, die mehr auf GUI und Benutzeroberfläche ausgerichtet ist. Diese Tools arbeiten an der Automatisierung der darunterliegenden Dienste, sodass die Workloads die Interaktion mit den Diensten steuern.
Dienstleistungen werden traditionell in drei Hauptkategorien eingeteilt: Anwendungen wie Standardprodukte wie Word oder eine SAP-Anwendung; komplexe Dienstleistungen, die für einen bestimmten Zweck entwickelt wurden, wie zum Beispiel ein MEAN-Stack mit Mongo; und einfache Dienstleistungen, die eine einzige Funktion erfüllen, zum Beispiel MongoDB, das die Datenbank speichert.
Es gibt eine neue Kategorie aufgrund des Wachstums von KI und ML. Viele Dienste haben ohne ein Anhängermodell nicht viel zu bieten, daher haben wir KI-Modelle in die Dienstebene integriert, die wir ähnlich wie einen einfachen Service behandeln.
Entwicklertag im Leben
Nachdem wir die Arbeitsbelastung und die Services verstanden haben, können wir uns anschauen, was ein Entwickler normalerweise tut.
Ein Entwickler wird einige Codezeilen auf ihrer Workstation schreiben und einige Funktionalitätstests durchführen. Anschließend lädt er/sie den Code beispielsweise in GitHub hoch, und ein Continuous Integration Continuous Delivery (CICD) Pipeline wird gestartet. Dabei werden Sicherheitschecks gegen den Code durchgeführt, möglicherweise Linting, statische Analyse und dynamische Analyse.
Sobald es diese Tests besteht, wird es normalerweise in einen Integrationszweig überführt, in dem andere Personen im Entwicklungsteam die Daten abrufen und diese entwickeln und ihren Code mit dem Code des Entwicklers integrieren. Anschließend, wenn es ihre Tests besteht, wird es in eine Testphase überführt. Sobald diese Phase abgeschlossen ist, wird es in die Produktion übernommen.
Dies ist eine typische CICD-Pipeline, die seit Jahrzehnten besteht. Im Laufe der Jahre wurden die verschiedenen Arten, Pipelines zu beschreiben, vereinheitlicht und standardisiert, um Komplexitäten und Fehler zu minimieren.
DevSecOps Stapel
Die Pipeline ist nur ein Element eines SecDevOps-Stapels.
Andere notwendige Elemente sind ein Register und ein Repository. Denken Sie an diese als versionierte Repositories, um Artefakte zu speichern, die während der CICD-Pipeline generiert werden, sodass sie leicht wieder verwendet werden können.
Ein weiteres wichtiges Element ist ein Automatisierungsframework. Dieses hilft, die menschliche Arbeitsbelastung bei Aufgaben wie Sicherheitsprüfungen oder dem Vorantreiben von Builds von einer Stufe zur nächsten zu reduzieren. Die Tools zur Automatisierung sind fortgeschritten und Schulungen stehen zur Verfügung. Daher sollte ein gutes Automatisierungsframework grundlegend sein.
Obwohl das Umweltmanagement oft organisch mit der Zeit wächst, ist es sinnvoll, die Umgebungen angemessen zu verwalten und zu gestalten, um mehr Zuverlässigkeit und Wiederholbarkeit zu erreichen.
Ein entscheidendes Element darunter ist ein Sicherheitsprofil. Sie sollten in der Lage sein, Sicherheitsprofile zu definieren, damit sie in verschiedenen Umgebungen und über verschiedene Anwendungsstapel hinweg verwendet werden können.
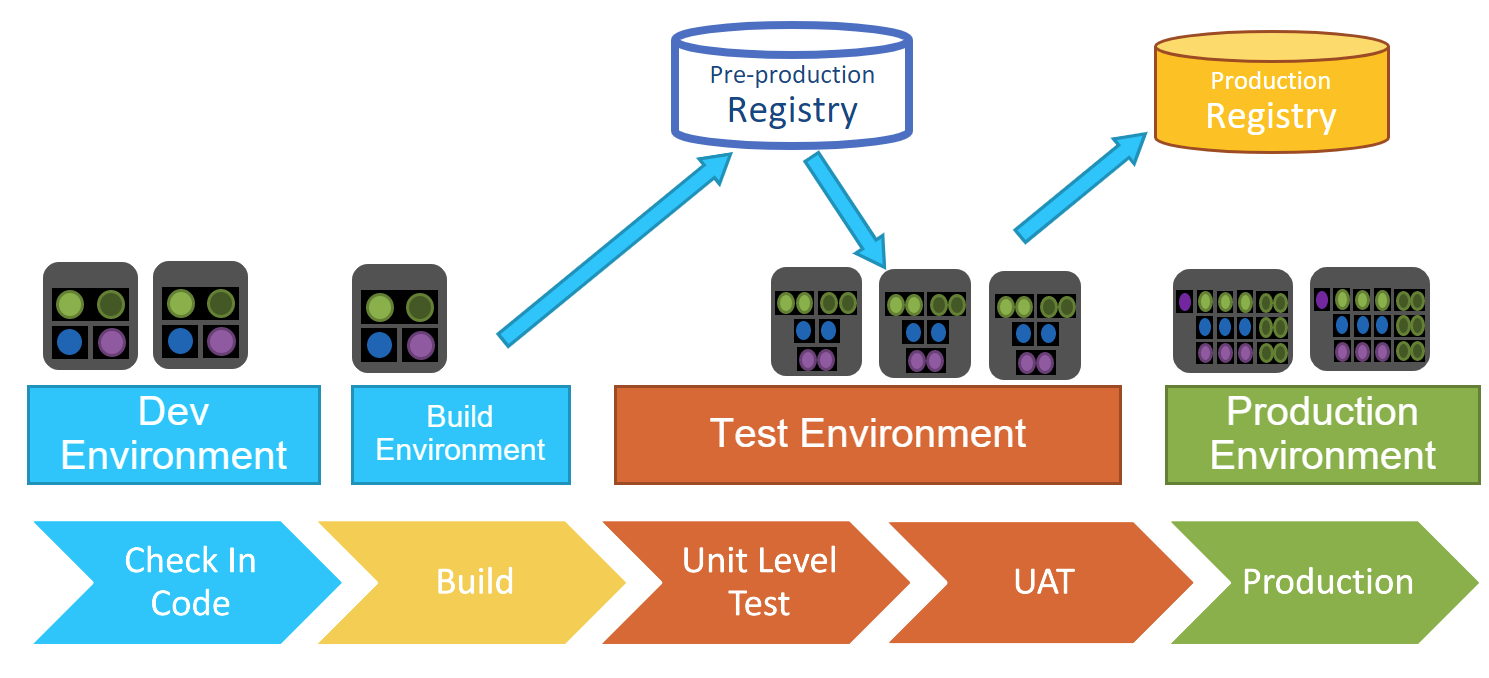
Register / Datenbanken
In der Regel gibt es mindestens zwei verschiedene Arten von Repositories. Das erste ist ein Staging-Repository, in dem man Bilder erstellen kann (eine Sammlung des gesamten Codes, der benötigt wird, um einen Container zum Beispiel hochzufahren) und Dinge wie Identitäts- und geheime Schlüssel speichern kann. Dieses Repository enthält alles, was man braucht, um Dinge in die Produktion zu bringen. Einige Organisationen können mehrere Staging-Repositories haben, während verschiedene Elemente unterschiedliche Reifestadien durchlaufen, bis sie das Produktions-Repository erreichen. Man möchte in der Lage sein, zu früheren Versionen zurückzukehren, wenn nötig.
In der Produktions- oder Golden-Repository werden Bilder gesperrt, beglaubigt und verschlüsselt. Nur Dinge, die sich im Golden-Repository befinden, werden in die Produktion übertragen.
Stufen
Der beste Weg, um die Phasen in der CICD-Pipeline zu betrachten, ist, dass jede Phase in einer eigenen Umgebung arbeitet. Zum Beispiel gibt es in der Build-Phase eine isolierte Build-Umgebung mit Richtlinien. Erst wenn alle Schritte in dieser Phase abgeschlossen sind, kann es zur nächsten Phase übergehen. Dies vermeidet den Ressourcenverbrauch durch parallele Builds und Durchläufe, die letztendlich scheitern könnten. Gleichzeitig ist es am besten, nicht so viele Phasen zu haben, dass sie den Fortschritt behindern, daher ist ein sorgfältiger, definierter Plan wichtig.
Schritte
In den Stufen befinden sich Schritte, in denen die eigentliche Arbeit erledigt wird. Beim Erstellen und Testen der Software können Schritte parallel oder in Abfolge ausgeführt werden; es gibt viele Tools, mit denen Sie diese Vorgänge definieren können. Obwohl einige eine grafische Benutzeroberfläche dafür haben, bevorzugen die meisten Entwickler ein textbasiertes Format, da es eine Versionskontrolle der Pipeline und der Schritte ermöglicht und Sicherheitsüberprüfungen gegen die Pipeline erlaubt.
Pipeline
Mit definierten Stufen und Schritten haben Sie eine echte Pipeline. Anstatt eine Pipeline für alle Ihre Anwendungen zu definieren, was in der Regel scheitert, weil sie mit vielen Bedingungen zu komplex oder zu einschränkend wird, empfehle ich, Vorlagenaufträge zu verwenden und sie bei Bedarf anzupassen, um sicherzustellen, dass sie den Compliance-Standards und Vorschriften entsprechen. Es ist wichtig, zu Beginn eines Projekts eine passende Pipeline einzurichten und gleichzeitig Flexibilität während des Projektfortschritts zu wahren.
Umgebungen
Anstatt ad-hoc-Umgebungen zu erstellen, ist es am besten, sie von vornherein absichtlich zu erstellen. DevOps oder SecDevOps können Sicherheitsrichtlinien und Compliance in allen verschiedenen Projekten implementieren, um Sicherheit zu gewährleisten.
Service Stack
Lassen Sie uns betrachten, wie Entwickler heutzutage arbeiten, was auf Diensten beruht. Selbst wenn Entwickler in einer monolithischen Anwendung arbeiten, neigen sie dazu, ihre Arbeit in funktionale Einheiten wie Datenbanken, Business-Logik-Knoten oder Transportebenen zu gruppieren. Zum Beispiel bei der Verwendung eines einfachen Dienstes wie MongoDB. Wenn ein Entwickler diesen Container auf seinem Laptop ausführt, bietet er die erwartete Funktionalität, um Daten auf dokumentenorientierte Weise zu speichern. Auf dem Laptop könnte es der einzige ausgeführte Container sein.
In einer Test- oder Entwicklungs-Umgebung könnten mehrere Instanzen dieses Dienstes ausgeführt werden, und der Entwickler könnte einen MongoDB-Service-Cluster bereitstellen und sie für einen Test miteinander verbinden. Der Service ist immer noch ein Mongo-DB-Service, aber sein Verhalten ändert sich basierend auf der Umgebung, in der er sich befindet. Das Ziel für Entwickler besteht darin, Code zu schreiben und ihn gegen den MongoDB-Service auf ihren Laptops zu überprüfen, um sicherzustellen, dass er auch in der Produktion ordnungsgemäß ausgeführt wird.
Ein einfacher Dienst wie MongoDB ist notwendig, aber für sich allein nicht besonders nützlich. Komplexe Dienste wie LAMP-Stacks oder MEAN-Stacks sind wichtiger. Diese bestehen aus mehreren gemeinsam ausgeführten Diensten und fungieren im Wesentlichen als ein Dienst. Wenn sie zusammengefasst werden, wird ein komplexer Dienst auf einem Laptop bereitgestellt und es gibt zwei oder drei einfache Dienstcontainer, die laufen und Entwicklern die erforderliche Funktionalität bieten, um ihren Code einzuchecken.
Sobald der Code eingecheckt ist, startet er in die Entwicklungs-Pipeline, in der der Entwickler mit anderen Personen integriert. Der gleiche komplexe Service kann verschiedene Vorgehensweisen annehmen. Viele Sicherheitsrichtlinien können diesem komplexen Service zugewiesen werden, um sicherzustellen, dass er sicher, zuverlässig und belastbar ist.
Service/Application Definitions: Dienst-/Anwendungsdefinitionen
Es ist wichtig, die Konzepte einfacher und komplexer Dienste zu verstehen, da Softwareentwickler definieren müssen, wie man sie zum Laufen bringt. Es gibt ein paar Definitionen. Eine davon wird als Bilddefinition bezeichnet. Diese kommen häufig in der Containerwelt vor und werden Docker-Images genannt. Die Docker-Datei definiert, was in diesem Bild enthalten ist. Es gilt als einfacher Container an sich, obwohl immer mehr Menschen Container für komplexe Aufgaben verwenden.
In Service-Definitionen können mehrere Imaginationsdefinitionen enthalten sein, zum Beispiel Docker Compose, Kubernetes Operators, Helm Charts, Terraform und sogar CNAB. Dies sind Werkzeuge, mit denen du einen Service definieren kannst. Ein Service ist mehr als nur der Container; es ist die Umgebung, in der der Container läuft. Sie können Netzwerkdefinitionen, Volumenverbindungen oder sogar Bereitstellungspolicies enthalten. Eine vollständige “Service-Definition” umfasst Image-, Konfigurations- und Bereitstellungsdefinitionen.
Alles zusammenfügen
Wenn ein Entwickler einen neuen Service erstellt, erstellt er nicht nur den Code für das Abbild; er definiert auch die Umgebung oder Konfiguration, in der dieser ausgeführt werden soll. Dies ist der Punkt, an dem sich Ihre Umgebung und die Service-Definition verbinden können. Zur Laufzeit wird es die Umgebung erzeugen, die erforderlich ist, damit der Container auf effektive Weise wiederholbar ausgeführt werden kann, sodass Sie den Code problemlos von einem Desktop-System in eine vollständige Produktionsumgebung verschieben können.