#23 Creazione di intuizioni nelle organizzazioni incentrate sui dati
Subscribe to get the latest
on 2020-09-30 00:00:00 +0000
with Darren W Pulsipher, Sarah Kalicin,
Nella parte 5 di una serie, Kick-starting your Organizational Transformation to Become Data Centric, Sarah Kalicin, Lead Data Scientist, Intel, e Darren Pulsipher, Chief Solutions Architect, Public Sector, Intel, discutono di come creare conoscenze utilizzando l'IA e l'apprendimento automatico in un'organizzazione orientata ai dati.
Keywords
#artificialintelligence #multicloud #people #process #technology
Utilizzando come esempio la produzione di widget, Darren e Sarah hanno precedentemente discusso del flusso di dati nel tentativo di rispondere a una domanda fondamentale per il business: Quanti widget produrre. La complessità diventa evidente quando si tratta di prendere i dati grezzi della domanda dei clienti, dell’offerta attuale e della perdita di resa e trasformarli in informazioni.
Il primo passo di questo processo, prima di poter decidere quali strumenti utilizzare, consiste nel preparare i dati in una forma utilizzabile. L’ottanta o novanta percento del lavoro di uno scienziato dei dati consiste nella preparazione e trasformazione dei dati in modo che possano essere inseriti in un algoritmo, ad esempio, o utilizzati per il riconoscimento di pattern.
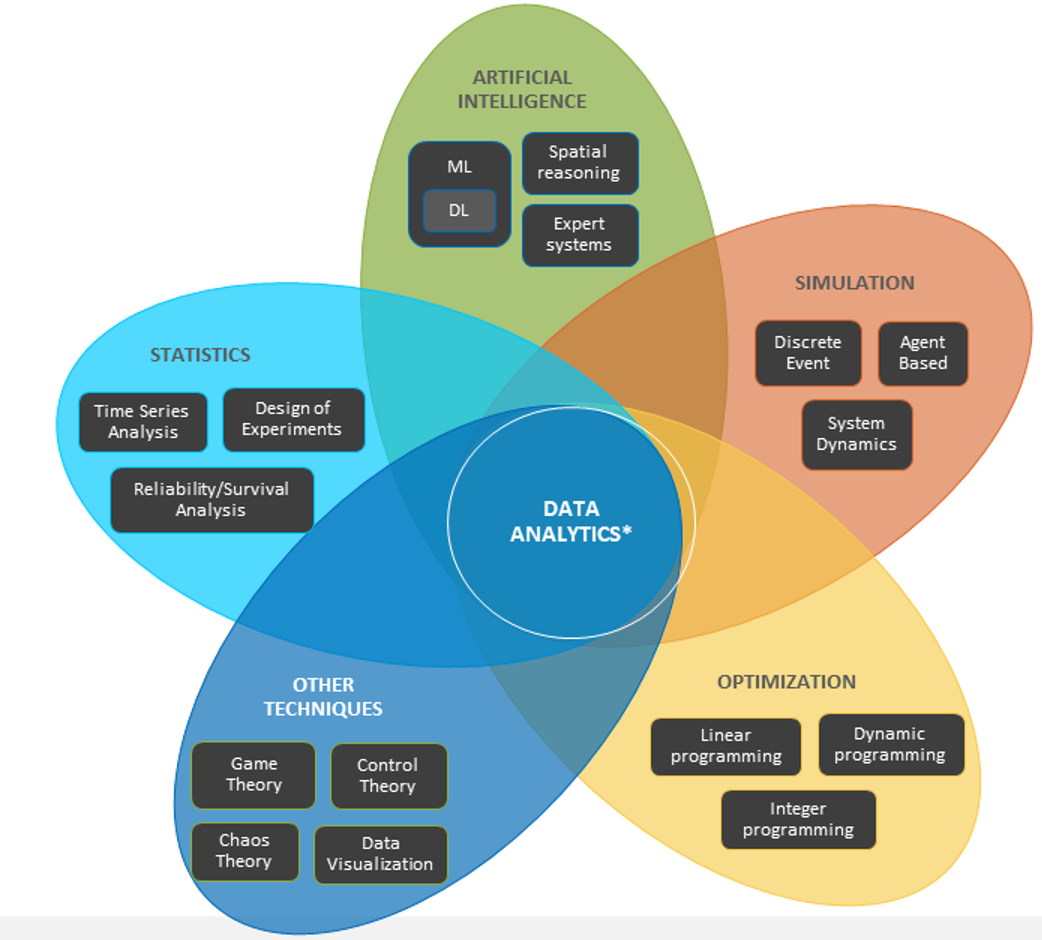
Gli strumenti corretti sono complessi. Intelligenza artificiale e apprendimento automatico non utilizzano un singolo algoritmo, ma una pletora di strumenti che gli scienziati dei dati usano e sperimentano in combinazioni per ottenere i migliori risultati di analisi. In altre parole, un singolo algoritmo non ti dirà quanti widget dovresti produrre. Ci sono molte parti sovrapposte e gli strumenti stessi sono complessi. Inoltre, gli scienziati dei dati hanno diverse aree di specializzazione; la scienza dei dati è uno sport di squadra. Proprio come non assegneresti a un ingegnere di rete la progettazione dell’architettura di archiviazione, non impiegheresti un ingegnere di deep learning specializzato nel riconoscimento delle immagini per risolvere il problema dell’analisi di rendimento. Devi assumere gli scienziati dei dati giusti per progettare e implementare gli strumenti giusti per ottenere un’analisi dei tuoi quesiti aziendali.
Torniamo alla questione di quante widget dovresti produrre. Ogni situazione e modello saranno ovviamente diversi in base ai tipi di domande, dati e dinamiche che hai, ma useremo questo come punto di partenza. Una volta stabilita questa domanda aziendale, l’organizzazione passerà attraverso uno sviluppo di maturità analitica.
Innanzitutto, ti concentrerai su ciò che è accaduto in passato per individuare i modelli nella domanda dei tuoi widget. Ad esempio, potresti analizzare dati in serie storiche per capire quando la domanda di widget aumenta o diminuisce. Quanto stabile è l’informazione nel tempo e come puoi utilizzarla per fare previsioni sul futuro? Forse potresti utilizzare l’apprendimento automatico per analizzare differenti segmenti temporali e comprenderli. Potresti anche voler fare un’analisi del testo per capire se le persone parlano dei tuoi widget sui social media. Il numero di like o condivisioni potrebbe essere una fonte di dati.
Potresti fare qualcosa di simile con l’approvvigionamento. Quanto stabile è l’attuale approvvigionamento e quanto bene comprendi la dinamica del sistema? Guarda dove hai bisogno di un essere umano per capire la dinamica del sistema e incorpora quella conoscenza nel modo in cui fai le tue analisi. Potrebbero esserci alcuni modelli di apprendimento automatico che ti danno delle idee di intuizione, quindi potresti fare dell’apprendimento non supervisionato. L’apprendimento non supervisionato consiste nel trovare se ci sono diverse categorie o segmenti di cui non sei consapevole che si comportano in modo diverso l’uno dall’altro. Chiediti come puoi tracciare meglio o ottenere una migliore risoluzione di ciò che sta accadendo in questi gruppi.
In breve, a seconda da dove provengono i dati e da cosa stai analizzando in quei dati, utilizzerai strumenti diversi.
La perdita di rendimento è un esempio della complessità dei problemi da risolvere. Più variazione nella linea di produzione, più sprechi possono verificarsi. In questo caso, il machine learning analizzerà segmenti e cluster di diversi tipi di rendimenti. Come si può quantificare e prevedere ciò?
Una cosa che i data scientist fanno qui è il design degli esperimenti per cercare di stimare la causalità. Girando manopole e azionando leve in modo sistematico, puoi vedere cosa succede al rendimento, aggiungendo allo stesso tempo controlli di processo per evitare deviazioni.
Un’altra opportunità per condurre analisi è l’affidabilità. Ad esempio, con la manutenzione predittiva, i tuoi strumenti di produzione possono essere mantenuti tempestivamente per evitare perdite nella produzione. Puoi inoltre utilizzare l’analisi dei testi in determinate situazioni, ad esempio quando hai registrazioni scritte di osservazioni e soluzioni dei tecnici nel tempo da utilizzare come base di conoscenza collettiva.
Il deep learning nell’ambito del riconoscimento delle immagini è un’altra strategia per aiutare a prevenire perdite mediante la rilevazione di errori e difetti, e forse anche la categorizzazione dei difetti.
L’obiettivo di tutto questo è, naturalmente, acquisire preziose intuizioni commerciali per la tua organizzazione. La chiave è l’impegno verso un’organizzazione incentrata sui dati, rimanendo flessibili e avendo gli strumenti e le persone giuste per trasformare i tuoi dati in intuizioni operative.