#23 Création d'aperçus dans les organisations axées sur les données
Subscribe to get the latest
on 2020-09-30 00:00:00 +0000
with Darren W Pulsipher, Sarah Kalicin,
Dans la partie 5 d'une série, Sarah Kalicin, scientifique en chef des données chez Intel, et Darren Pulsipher, architecte principal des solutions du secteur public chez Intel, expliquent comment créer des informations en utilisant l'IA et l'apprentissage automatique dans une organisation axée sur les données.
Keywords
#artificialintelligence #multicloud #people #process #technology
En utilisant l’exemple de la fabrication de widgets, Darren et Sarah ont précédemment discuté du pipeline de données dans le but de répondre à une question fondamentale pour l’entreprise : Combien de widgets produire. La complexité devient apparente lorsqu’il s’agit de prendre les données brutes de la demande des clients, de l’offre actuelle et de la perte de rendement, et de les convertir en informations.
La première étape de ce processus, avant de pouvoir décider des outils à utiliser, est de préparer les données sous une forme utilisable. Quatre-vingts ou quatre-vingt-dix pour cent du travail d’un scientifique des données consiste à préparer et à transformer les données afin de les mettre dans un algorithme, par exemple, ou de les utiliser pour la reconnaissance de motifs.
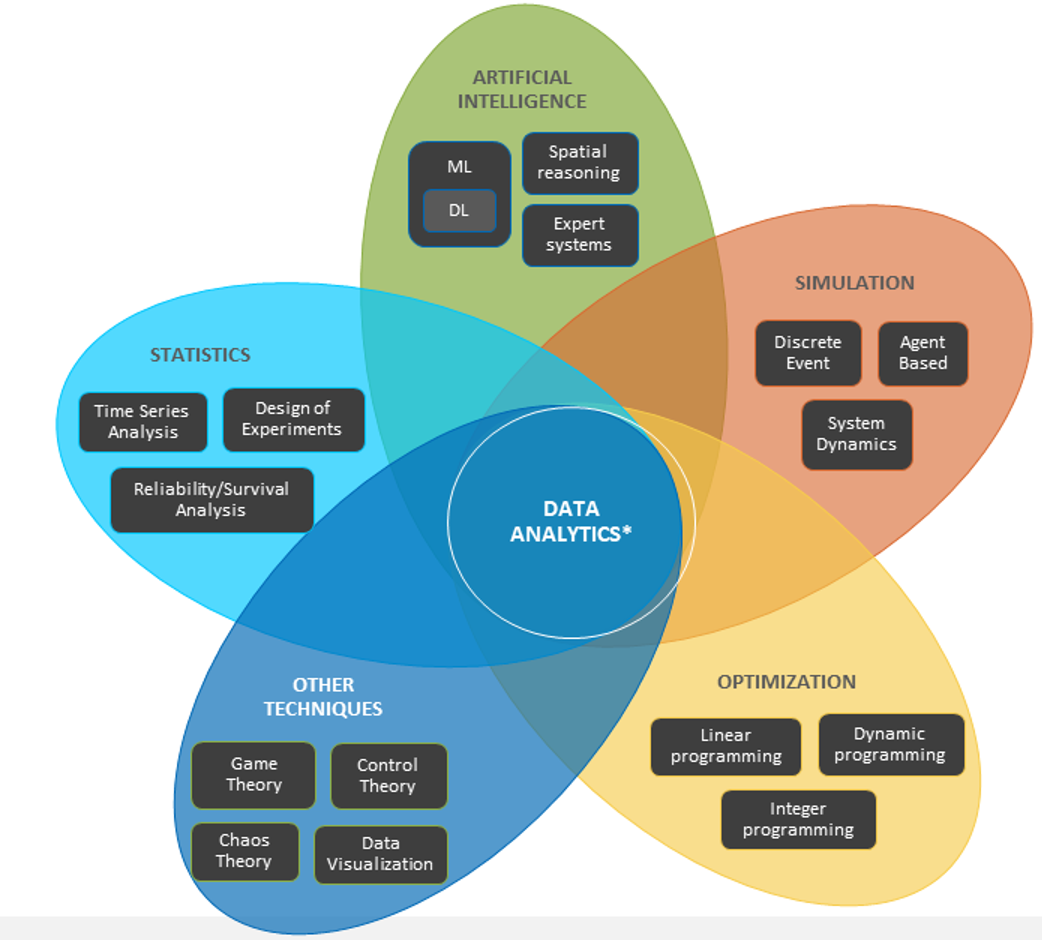
Les bons outils sont complexes. L’intelligence artificielle et l’apprentissage automatique n’utilisent pas un seul algorithme, mais une multitude d’outils que les scientifiques des données utilisent et expérimentent en combinaison pour obtenir les meilleurs résultats d’analyse. En d’autres termes, un seul algorithme ne vous dira pas combien d’objets vous devriez fabriquer. Il y a beaucoup de parties qui se chevauchent, et les outils eux-mêmes sont complexes. De plus, les scientifiques des données ont des domaines d’expertise différents ; la science des données est un sport d’équipe. Tout comme vous ne confieriez pas à un ingénieur réseau la conception de l’architecture de stockage, vous n’emploieriez pas un ingénieur spécialisé dans la reconnaissance d’images pour résoudre votre problème d’analyse de rendement. Vous devez embaucher les scientifiques des données appropriés pour concevoir et déployer les bons outils afin d’obtenir des informations sur vos questions commerciales.
Revenons à la question du nombre de widgets que vous devriez fabriquer. Chaque situation et modèle seront bien sûr différents en fonction des types de questions, de données et de dynamiques que vous avez, mais nous le prendrons comme point de départ. Une fois que cette question commerciale est établie, l’organisation passera par un développement de maturité analytique.
D’abord, vous vous concentrerez sur ce qui s’est passé dans le passé pour repérer les tendances de la demande de vos widgets. Par exemple, vous pourriez examiner des données chronologiques pour voir quand la demande de widgets augmente et diminue. Dans quelle mesure les informations sont-elles stables au fil du temps et comment pouvez-vous les utiliser pour prévoir l’avenir ? Peut-être pourriez-vous utiliser un apprentissage automatique pour étudier différents segments temporels et les comprendre. Vous voudrez peut-être également effectuer une analyse de texte pour savoir si les gens parlent de votre widget sur les médias sociaux. Le nombre de “j’aime” ou de partages pourrait être une source de données.
Vous pourriez faire quelque chose de similaire avec l’approvisionnement. Quelle est la stabilité de l’approvisionnement actuel et à quel point comprenez-vous bien la dynamique du système ? Regardez où vous avez besoin d’un humain pour comprendre la dynamique du système et incorporez cette connaissance dans la façon dont vous effectuez vos analyses. Il pourrait y avoir des types de modèles d’apprentissage automatique qui vous donnent des idées de perspectives, vous pourriez donc faire de l’apprentissage non supervisé. L’apprentissage non supervisé consiste à déterminer s’il existe différentes catégories ou segments dont vous n’êtes pas conscient et qui se comportent différemment les uns des autres. Demandez comment vous pouvez mieux suivre, ou obtenir une meilleure résolution de ce qui se passe dans ces groupes.
En résumé, selon la provenance des données et ce que vous regardez dans ces données, vous allez utiliser des outils différents.
La perte de rendement est un exemple de la complexité des problèmes à résoudre. Plus il y a de variations dans la chaîne de fabrication, plus il peut y avoir de gaspillage. Dans ce cas, l’apprentissage automatique examinera les segments et les regroupements des différents types de rendements. Comment quantifier et prédire cela ?
Une des tâches des scientifiques des données ici est la conception d’expériences afin d’essayer d’estimer la causalité. En manipulant des boutons et en actionnant des leviers de manière systématique, vous pouvez observer ce qui se produit au niveau du rendement, tout en ajoutant des commandes de processus pour éviter les dérives.
Une autre opportunité d’analyse est la fiabilité. Par exemple, avec la maintenance prédictive, vos outils de fabrication peuvent être entretenus en temps opportun pour éviter toute perte de rendement. Vous pouvez également utiliser l’analyse textuelle dans certaines situations, comme lorsque vous disposez d’observations et de solutions écrites de techniciens au fil du temps, à utiliser comme base de connaissances collective.
L’apprentissage profond autour de la reconnaissance d’image est une autre stratégie pour aider à prévenir les pertes en détectant les erreurs et les défauts, et peut-être même pour la catégorisation des défauts.
L’objectif de tout cela est, bien sûr, de gagner une précieuse compréhension du monde des affaires pour votre organisation. La clé est l’engagement envers une organisation centrée sur les données, en restant flexible et en disposant des bons outils et des bonnes personnes pour transformer vos données en aperçus exploitables.