#23 Creación de perspicacia en organizaciones centradas en datos
Subscribe to get the latest
on 2020-09-30 00:00:00 +0000
with Darren W Pulsipher, Sarah Kalicin,
En la parte 5 de una serie, Kick-starting your Organizational Transformation to Become Data Centric, Sarah Kalicin, Lead Data Scientist, Intel, y Darren Pulsipher, Chief Solutions Architect, Public Sector, Intel, discuten cómo crear conocimiento utilizando inteligencia artificial y aprendizaje automático en una organización centrada en los datos.
Keywords
#artificialintelligence #multicloud #people #process #technology
Utilizando el ejemplo de la fabricación de widgets, Darren y Sarah hablaron previamente sobre el flujo de datos en un esfuerzo por responder una pregunta fundamental de negocios: ¿Cuántos widgets producir? La complejidad se vuelve evidente cuando se trata de tomar los datos crudos de la demanda de clientes, la oferta actual y las pérdidas de rendimiento, y convertirlos en información.
El primer paso en este proceso, antes de poder decidir qué herramientas usar, es preparar los datos en una forma utilizable. Ochenta o noventa por ciento del trabajo de un científico de datos se dedica a preparar y transformar los datos para poder ponerlos en un algoritmo, por ejemplo, o usarlos para el reconocimiento de patrones.
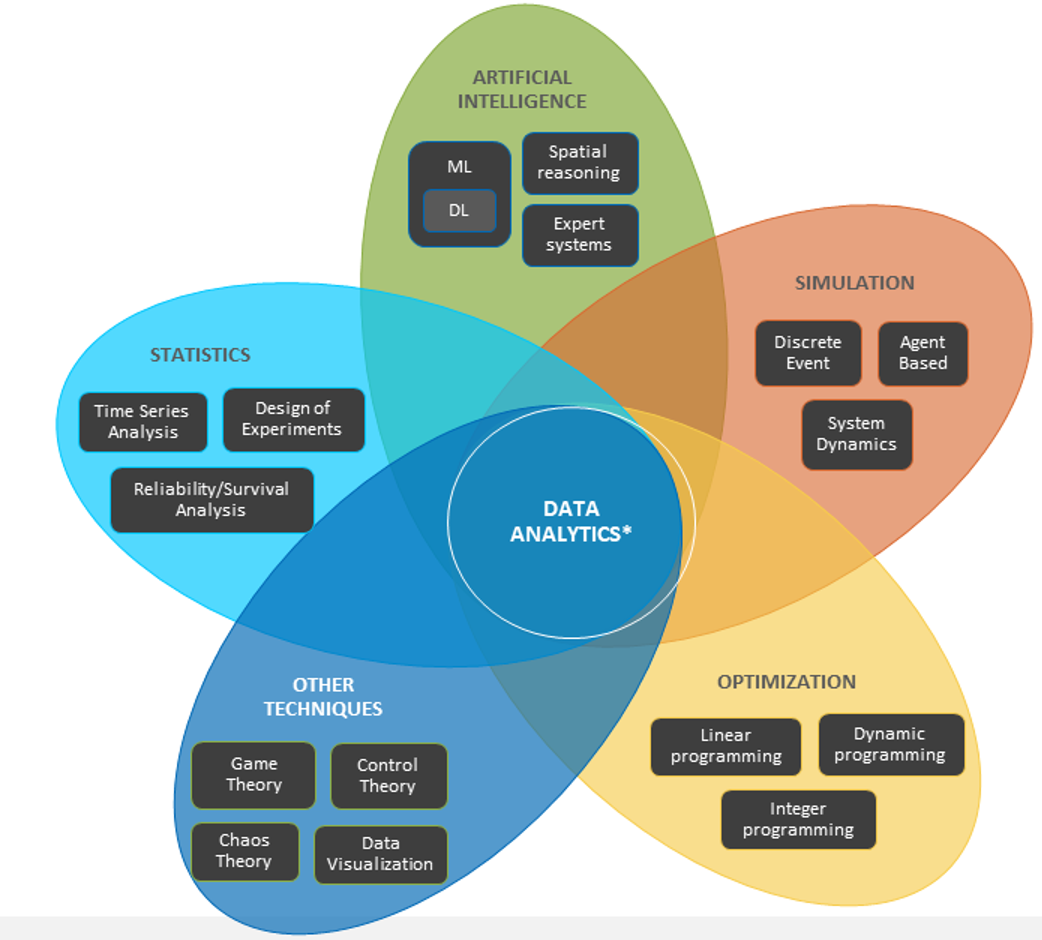
Las herramientas adecuadas son complejas. La inteligencia artificial y el aprendizaje automático no utilizan un único algoritmo, sino una gran cantidad de herramientas que los científicos de datos utilizan y experimentan en combinaciones para obtener los mejores resultados de información. En otras palabras, un solo algoritmo no te dirá cuántos widgets debes fabricar. Hay muchas partes superpuestas y las propias herramientas son complejas. Además, los científicos de datos tienen diferentes áreas de especialización; la ciencia de datos es un deporte en equipo. Así como no le asignarías a un ingeniero de redes el diseño de la arquitectura de almacenamiento, no contratarías a un ingeniero de aprendizaje profundo especializado en reconocimiento de imágenes para resolver tu problema de análisis de rendimiento. Tienes que contratar a los científicos de datos adecuados para diseñar e implementar las herramientas adecuadas y obtener información sobre tus preguntas comerciales.
Volviendo a la pregunta de cuántos widgets debes fabricar. Cada situación y modelo serán diferentes, por supuesto, en función de los tipos de preguntas, datos y dinámicas que tengas, pero utilizaremos esto como punto de partida. Una vez que se establezca esta pregunta empresarial, la organización atravesará un desarrollo de madurez analítica.
Primero, te enfocarás en lo que ha sucedido en el pasado para observar patrones en la demanda de tus widgets. Por ejemplo, podrías examinar datos de series de tiempo para ver cuándo aumenta o disminuye la demanda de widgets. ¿Qué tan estable es la información a lo largo del tiempo y cómo puedes utilizarla para predecir el futuro? Tal vez podrías utilizar aprendizaje automático para analizar diferentes segmentos de tiempo y comprenderlos. También podrías realizar análisis de texto para determinar si las personas están hablando de tu widget en las redes sociales. El número de likes o compartidos podría ser una fuente de datos.
Podrías hacer algo similar con el suministro. ¿Qué tan estable es el suministro actual y cuánto comprendes la dinámica del sistema? Observa dónde necesitas a una persona para entender la dinámica del sistema e incorpora ese conocimiento en la forma en que realizas tus análisis. Podría haber algún tipo de patrones de aprendizaje automático que te den ideas de conocimiento, por lo que podrías realizar un aprendizaje no supervisado. El aprendizaje no supervisado consiste en encontrar si hay diferentes categorías o segmentos de los que no eres consciente y que se comportan de manera diferente entre sí. Pregunta cómo puedes realizar un mejor seguimiento o obtener una mejor resolución de lo que está sucediendo en estos grupos.
En resumen, dependiendo de dónde venga los datos y de lo que estés observando en esos datos, vas a utilizar diferentes herramientas.
La pérdida de rendimiento es un ejemplo de la complejidad de los problemas que deben ser resueltos. Cuanta más variación haya en la línea de producción, más desperdicio puede ocurrir. En este caso, el aprendizaje automático estará enfocado en segmentos y grupos de diferentes tipos de rendimientos. ¿Cómo se cuantifica y predice eso?
Una de las cosas que los científicos de datos hacen aquí es el diseño de experimentos para tratar de estimar la causalidad. Al girar perillas y accionar palancas de manera sistemática, puedes observar qué sucede con el rendimiento, al mismo tiempo que añades controles de proceso para evitar desviaciones.
Otra oportunidad para realizar análisis es la confiabilidad. Por ejemplo, con el mantenimiento predictivo, se pueden mantener las herramientas de fabricación de manera oportuna para prevenir la pérdida de rendimiento. También se puede utilizar el análisis de texto en ciertas situaciones, como cuando se tienen registros escritos de observaciones y soluciones de técnicos a lo largo del tiempo, para utilizar como base de conocimiento colectiva.
El aprendizaje profundo en torno al reconocimiento de imágenes es otra estrategia para ayudar a prevenir pérdidas mediante la detección de errores y defectos, e incluso posiblemente la categorización de defectos.
El objetivo de todo esto es, por supuesto, obtener conocimientos comerciales valiosos para tu organización. La clave es comprometerse con una organización centrada en los datos, mantenerse flexible y contar con las herramientas adecuadas y las personas adecuadas para convertir tus datos en información valiosa y accionable.