#23 Erkenntnisschaffung in datenzentrierten Organisationen
Subscribe to get the latest
on 2020-09-30 00:00:00 +0000
with Darren W Pulsipher, Sarah Kalicin,
Im Teil 5 einer Serie, Umgestaltung Ihrer Organisation in eine datenzentrierte Organisation mittels Kickstart, diskutieren Sarah Kalicin, Leitende Datenwissenschaftlerin bei Intel, und Darren Pulsipher, Chef-Solutions-Architekt im öffentlichen Sektor bei Intel, wie man mithilfe künstlicher Intelligenz und maschinellem Lernen Erkenntnisse in einer datenzentrierten Organisation schafft.
Keywords
#artificialintelligence #multicloud #people #process #technology
Unter Verwendung des Beispiels der Herstellung von Widgets diskutierten Darren und Sarah zuvor über die Datenpipeline in dem Bestreben, eine grundlegende Geschäftsfrage zu beantworten: Wie viele Widgets sollen produziert werden? Die Komplexität wird deutlich, wenn es darum geht, die Rohdaten für die Kundennachfrage, die aktuelle Versorgung und den Ausschuss in Erkenntnisse umzuwandeln.
Der erste Schritt in diesem Prozess, bevor Sie entscheiden können, welche Werkzeuge Sie verwenden möchten, besteht darin, die Daten in eine verwendbare Form vorzubereiten. Achtzig oder neunzig Prozent der Arbeit eines Datenwissenschaftlers besteht darin, die Daten vorzubereiten und zu transformieren, sodass sie beispielsweise in einen Algorithmus eingesetzt oder zur Mustererkennung verwendet werden können.
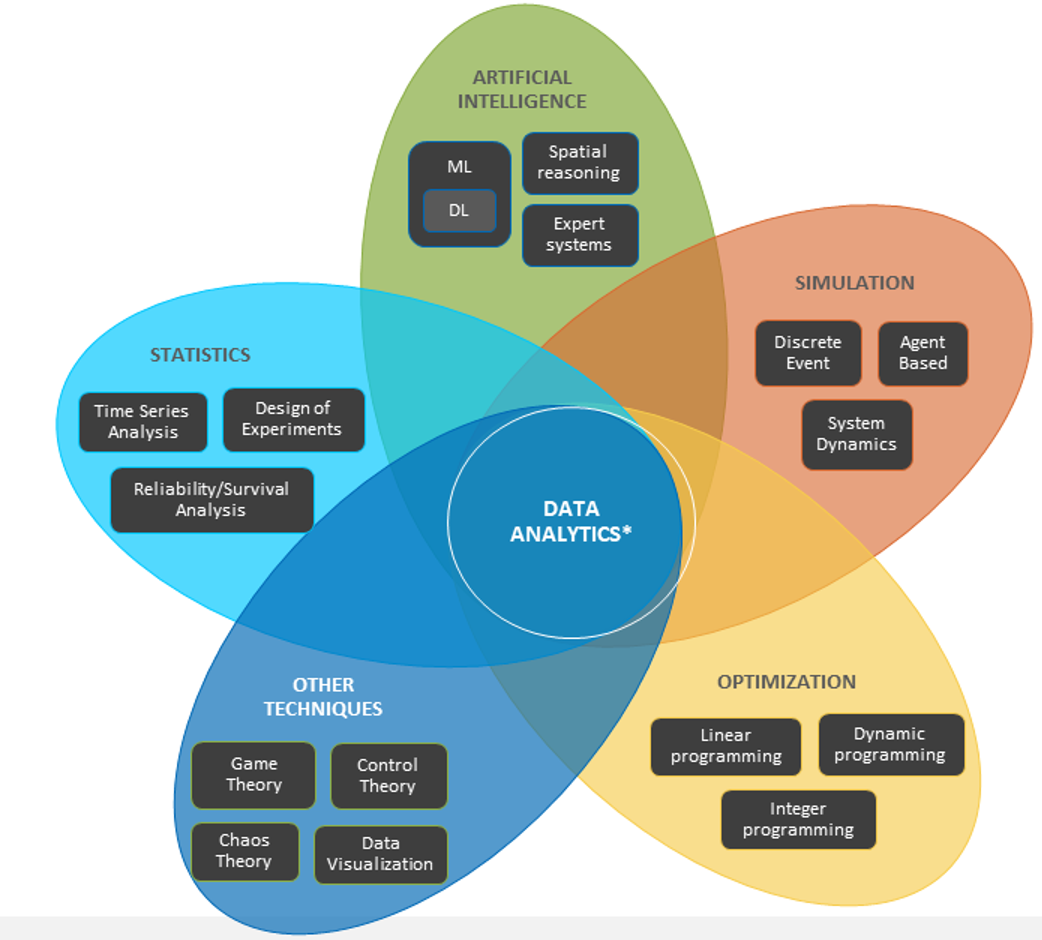
Die richtigen Werkzeuge sind komplex. KI und maschinelles Lernen verwenden nicht nur einen einzigen Algorithmus, sondern eine Vielzahl von Werkzeugen, die Datenwissenschaftler verwenden und kombinieren, um die besten Erkenntnisse zu erhalten. Mit anderen Worten, ein einziger Algorithmus wird Ihnen nicht sagen, wie viele Widgets Sie herstellen sollten. Es gibt viele überlappende Teile und die Werkzeuge selbst sind komplex. Darüber hinaus haben Datenwissenschaftler unterschiedliche Fachgebiete; Datenwissenschaft ist ein Teamsport. Genau wie Sie keinen Netzwerkingenieur mit dem Entwurf der Speicherarchitektur beauftragen würden, würden Sie keinen Deep-Learning-Ingenieur beschäftigen, der auf Bilderkennung spezialisiert ist, um Ihr Ausbeuteanalyse-Problem zu lösen. Sie müssen die richtigen Datenwissenschaftler einstellen, um die richtigen Werkzeuge zu entwerfen und einzusetzen, um Einblicke in Ihre geschäftlichen Fragen zu erhalten.
Lassen Sie uns zurück zur Frage gehen, wie viele Widgets Sie herstellen sollten. Jede Situation und jedes Modell wird natürlich unterschiedlich sein, je nach den Arten von Fragen, Daten und Dynamiken, die Sie haben, aber wir werden dies als Ausgangspunkt nutzen. Sobald diese geschäftliche Frage feststeht, wird die Organisation eine Entwicklung der analytischen Reife durchlaufen.
Zuerst konzentrieren Sie sich darauf, was in der Vergangenheit passiert ist, um Muster in der Nachfrage nach Ihren Widgets zu erkennen. Zum Beispiel könnten Sie sich einige Zeitreihendaten ansehen, um herauszufinden, wann die Nachfrage nach Widgets steigt und fällt. Wie stabil sind die Informationen im Laufe der Zeit und wie können Sie sie nutzen, um die Zukunft vorherzusagen? Vielleicht könnten Sie hierzu etwas maschinelles Lernen durchführen, um verschiedene Zeitabschnitte zu betrachten und sie zu verstehen. Möglicherweise möchten Sie auch eine Textanalyse durchführen, um herauszufinden, ob Menschen in den sozialen Medien über Ihr Widget sprechen. Die Anzahl der Likes oder Shares könnte eine Datenquelle sein.
Sie könnten etwas Ähnliches mit der Versorgung tun. Wie stabil ist die aktuelle Versorgung und wie gut verstehen Sie die Systemdynamik? Schauen Sie sich an, wo Sie einen Menschen benötigen, um die Systemdynamik herauszufinden, und integrieren Sie dieses Wissen in Ihre Analysemethoden. Es könnten maschinelles Lernen Muster geben, die Ihnen Einblicke geben, daher könnten Sie etwas unüberwachtes Lernen betreiben. Unüberwachtes Lernen bedeutet festzustellen, ob es verschiedene Kategorien oder Segmente gibt, von denen Sie nichts wissen, die sich jedoch unterschiedlich verhalten. Fragen Sie, wie Sie besser verfolgen können oder eine bessere Auflösung dessen erreichen können, was in diesen Gruppen geschieht.
Kurz gesagt, je nachdem, woher die Daten stammen und worauf du in den Daten schaust, wirst du verschiedene Werkzeuge verwenden.
Ertragseinbußen sind ein Beispiel für die Komplexität der zu lösenden Probleme. Je mehr Variation in der Produktionslinie vorliegt, desto mehr Verschwendung kann auftreten. In diesem Fall wird maschinelles Lernen Segmente und Cluster verschiedener Arten von Erträgen betrachten. Wie lässt sich das quantifizieren und vorhersagen?
Eine Sache, die Datenwissenschaftler hier tun, ist das Design von Experimenten, um Kausalität zu schätzen. Indem man Knöpfe dreht und Hebel auf systematische Weise betätigt, kann man sehen, was mit dem Ergebnis geschieht, während man Prozesskontrollen hinzufügt, um Abweichungen zu vermeiden.
Eine weitere Gelegenheit zur Durchführung von Analysen ist die Zuverlässigkeit. Beispielsweise können Ihre Fertigungswerkzeuge mit präventiver Instandhaltung rechtzeitig gewartet werden, um Produktionsverluste zu verhindern. In bestimmten Situationen kann auch die Textanalyse eingesetzt werden, zum Beispiel wenn Sie schriftliche Aufzeichnungen von Beobachtungen und Lösungen von Technikern über einen längeren Zeitraum vorliegen haben, die als kollektive Wissensbasis genutzt werden können.
Tiefes Lernen im Bereich der Bilderkennung ist eine weitere Strategie, um Verluste durch Erkennen von Fehlern und Mängeln zu verhindern und möglicherweise sogar zur Kategorisierung von Defekten beizutragen.
Das Ziel all dessen ist natürlich, wertvolle Geschäftseinblicke für Ihre Organisation zu gewinnen. Der Schlüssel dazu ist die Verpflichtung zu einer datenzentrierten Organisation, Flexibilität zu bewahren und die richtigen Tools und die richtigen Personen zu haben, um Ihre Daten in handlungsfähige Einblicke umzuwandeln.