#185 Geschichte von datenzentrierten Anwendungen (neu aufgelegt)
Subscribe to get the latest
on 2024-02-08 08:00:00 +0000
with Darren W Pulsipher,
Die erste Folge dieses Podcasts wurde vor 185 Folgen veröffentlicht. In dieser Folge überarbeitet der Gastgeber Darren Pulsipher die erste Folge, um aktualisierte Informationen zur Geschichte der datenzentrierten Anwendungsentwicklung zu liefern. Er diskutiert, wie neue Technologien wie Edge Computing und KI die Datengenerierung beeinflusst haben und die Notwendigkeit einer besseren Datenverwaltung.
Keywords
#virtualization #cloudcomputing #datalineage #datamanagement #cybersecurity #zerotrust #multicloud
Frühe Datenverarbeitung
In den Anfängen der Informatik wurden Anwendungen entwickelt, um Daten von einer Form in eine andere wertvolle Ausgabe zu transformieren. Frühe Computer wie der ENIAC und Turings Maschine zum Brechen des Enigma-Codes arbeiteten, indem sie Daten aufnahmen, diese über eine Anwendung verarbeiteten und sie zur Speicherung ausgaben. Im Laufe der Zeit entwickelte sich die Technologie von spezialisierten Hardwaregeräten zu allgemeineren Systemen mit CPUs und Netzwerkfähigkeiten. Dies ermöglichte den Datenaustausch zwischen Systemen und somit neue Anwendungen.
Entstehung der Virtualisierung
In den 1990er und 2000er Jahren ermöglichte Virtualisierungstechnologie die vollständige Verkapselung ganzer Systeme in virtuelle Maschinen. Dies entkoppelte die Anwendung von der Hardware und erhöhte die Portabilität. Mit dem Aufkommen von Linux konnten virtuelle Maschinen nun auf handelsüblichen x86-Prozessoren laufen, was die Kosten senkte und die Eintrittsbarrieren verringerte. Die Virtualisierung erhöhte die Benutzerfreundlichkeit, brachte jedoch neue Bedenken bezüglich Sicherheit und Leistung mit sich.
Der Aufstieg des Cloud Computing
Cloud Computing basiert auf Virtualisierung und bietet einen einfachen, bedarfsgerechten Zugriff auf Computing-Ressourcen über das Internet. Dies ermöglichte es Organisationen, ihre Investitionsausgaben und Betriebskosten zu senken. Der Umzug in die Cloud bedeutete jedoch auch Herausforderungen in Bezug auf Sicherheit, Leistung und Integration. Das Pay-as-you-go-Modell der Cloud ermöglichte neue Anwendungsfälle und erleichterte insgesamt den Verbrauch von Technologieressourcen.
Containerisierung und neue Komplexität
Die Containerisierung hat Anwendungen weiter von der Infrastruktur abstrahiert, indem sie Apps zusammen mit ihren Laufzeiten, Konfigurationen und Abhängigkeiten verpackte - dies erhöhte die Portabilität und Komplexität bei der Verwaltung verteilter Anwendungen und Daten in verschiedenen Umgebungen. Die Lokalität der Daten wurde zu einem zentralen Anliegen und widersprach den Annahmen, dass Daten überall verfügbar sind. Diese Entwicklung hatte erhebliche neue Sicherheitsimplikationen zur Folge.
Neufokussierung auf Daten
Um diese Herausforderungen anzugehen, konzentrieren sich neue Architekturen wie Daten-Meshes und verteiltes Informationsmanagement auf Datenlokalität, Governance, Lebenszyklusmanagement und Orchestrierung. Daten müssen in Anwendungen, Infrastruktur und Benutzern kontextualisiert werden, um sicher Geschäftswert zu liefern. Technologien wie KI treiben das Datenwachstum in Edge-Umgebungen exponentiell voran. Robustere Datenmanagementfähigkeiten sind entscheidend, um Komplexität und Risiko zu überwinden.
Sicherheitsbedenken bei der Datenverteilung
Die Verteilung von Daten und Anwendungen über Edge-Umgebungen hat die Angriffsfläche massiv erhöht. Die Prinzipien des Null-Vertrauens werden angewendet, um die Sicherheit zu verbessern, wobei der Schwerpunkt auf Identitäts- und Zugangskontrollen sowie auf Erkennung, Verschlüsselung und Hardware-Vertrauenswurzeln liegt.
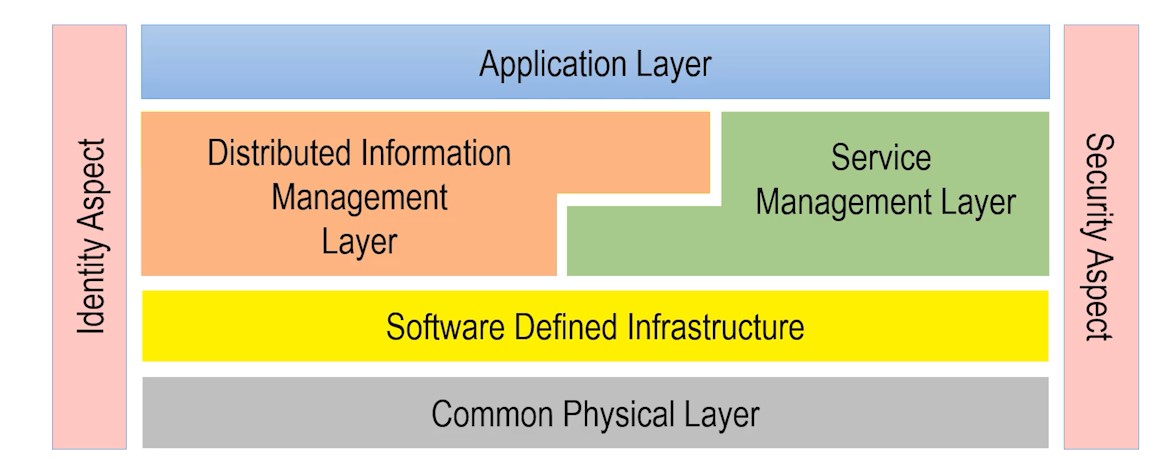
Die Edgemere Architektur
Die Edgemere-Architektur bietet ein Modell für die Implementierung von Sicherheit in modernen, komplexen Technologiestapeln, die Hardware, Virtualisierung, Cloud, Daten und Apps umspannen. Die ganzheitliche Anwendung von Zero-Trust-Prinzipien auf diese Schichten ist entscheidend für das Risikomanagement. Robuste Cybersicherheitsfunktionen wie Verschlüsselung und Zugangskontrollen sind unerlässlich, um einen Geschäftswert aus Daten in der neuen Ära von stark verteilten und vernetzten Systemen abzuleiten.