#18 Collecte et préparation des données
Subscribe to get the latest
on 2020-08-31 00:00:00 +0000
with Darren W Pulsipher,
Sarah Kalicin, Lead Data Scientist chez Intel et Darren Pulsipher, Architecte en chef des solutions du secteur public chez Intel, parlent du processus et des avantages de la collecte et de la préparation de données pour devenir une organisation axée sur les données. Il s'agit de la deuxième étape du parcours vers une organisation axée sur les données.
Keywords
#artificialintelligence #multicloud #process #technology
Nous avons besoin de données! Nos données sont désorganisées!
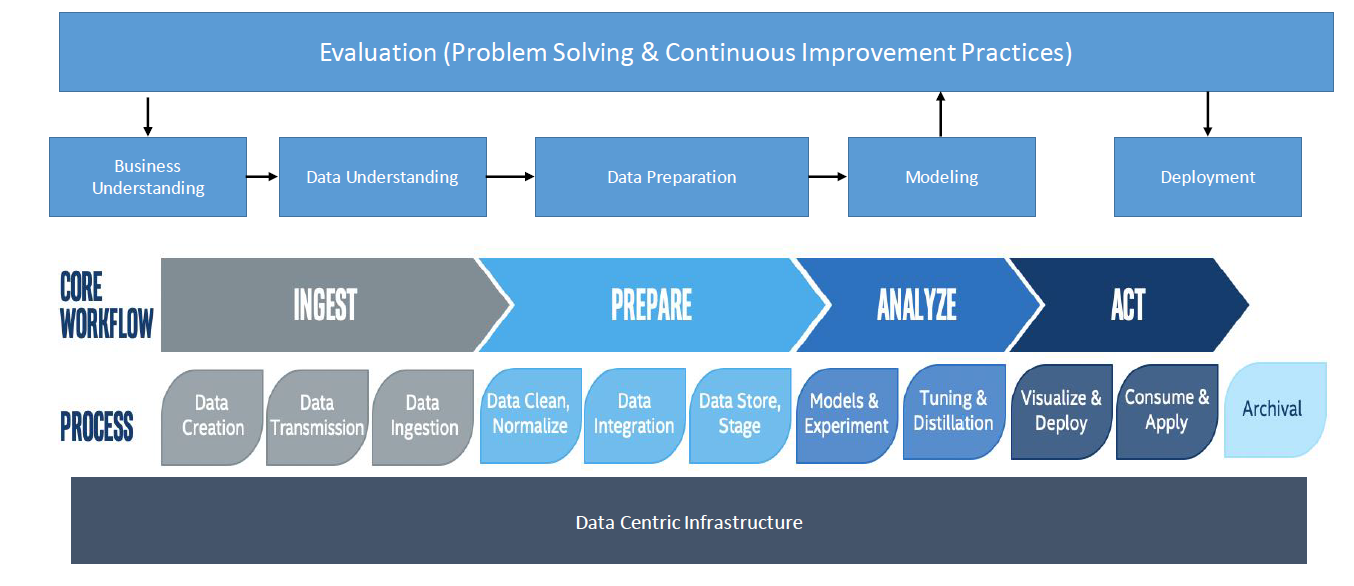
La première chose à considérer dans cette partie du processus est le pipeline de données. Comment identifions-nous les données brutes dont nous avons besoin et comment les faisons-nous passer à travers le pipeline et les transformons-nous en informations exploitables ? Il y a cinq étapes clés dans le pipeline : déterminer la valeur commerciale des données, les ingérer, les préparer, les analyser et enfin, agir en fonction des informations obtenues.
Jetons un coup d’œil à la fabrication, par exemple. Pour déterminer quelles données offrent une valeur commerciale, vous devriez vous poser trois questions fondamentales: Quelle est la demande pour mon widget ? Quelle est l’offre actuelle ? Quelles sont les pertes de rendement ? Ce sont des questions apparemment simples, mais ensuite vous devez réfléchir à des choses plus complexes, comme comment quantifier la demande, les capacités de fabrication, l’offre et les pertes de rendement ? D’où viennent les données ? Comment les intégrer ? Dans quelle mesure ces données sont-elles fiables et stables ? Il existe de nombreuses questions et variables, telles que le délai de livraison de la matière première, la demande prévue et les pertes de rendement inconnues, qui peuvent créer une grande complexité.
Le pipeline simplifie la façon dont tous ces composants se rassemblent. Chaque type de données passe par les étapes clés du pipeline, mais chacun sera différent. Par exemple, l’ingestion d’un type de données différera de celle d’un autre. L’idée, cependant, est de rassembler toutes les données pour créer une image claire.
Nous avons des données! Qu’en faisons-nous?
Selon le type de données et les questions auxquelles vous essayez de répondre, vous utiliseriez différentes techniques analytiques. Par exemple, pour répondre à la question du nombre de widgets à fabriquer, vous pourriez analyser l’offre et la demande historiques grâce à l’analyse de données et aux informations basiques sur l’entreprise. Pour déterminer quels widgets présentent des défauts visuels, il serait préférable d’utiliser un algorithme qui apprend à identifier les défauts sur des images grâce à l’apprentissage en profondeur. Il n’y a pas de technique universelle pour résoudre tous les problèmes ; chaque problème et chaque donnée sont uniques en leur genre.
De plus, il est important de faire appel à des experts du domaine pour aider à comprendre les schémas que les données révèlent. L’expert du domaine comprendra les données et leur provenance, tandis que le scientifique des données comprendra la meilleure approche pour les algorithmes afin d’obtenir plus d’informations. Par exemple, si une diminution du rendement du produit est prédite par un algorithme d’apprentissage automatique, les ingénieurs qui doivent corriger le problème ne sauront pas forcément où chercher sans le contexte du problème. Une des raisons pour lesquelles les organisations ne bénéficient pas du retour sur investissement qu’elles devraient obtenir est qu’elles n’ont pas conçu leurs modèles de manière à être opérationnels ou reflétant les comportements au sein des systèmes qu’elles essaient de prédire.
Comment tout cela fonctionne ensemble dépend des questions commerciales que vous posez et de vos défis. Par exemple, vous pourriez avoir une série d’algorithmes vous indiquant combien de widgets fabriquer. Vous pourriez avoir un algorithme d’apprentissage profond qui reconnaît si un widget présente un défaut, et qui classe même les défauts. Mais cela ne vous aide pas nécessairement si vous ne savez pas pourquoi ce défaut s’est produit. Vous devez donc lier ces informations à quelques autres algorithmes pour obtenir des corrélations afin d’expliquer les défauts, et vous avez besoin d’un plan d’action pour corriger le problème.
Nous devons créer des connaissances. Comment formons-nous nos données ?
Comment pouvons-nous accomplir cela? Fondamentalement, vous rassemblez toutes les données, les préparez et les reliez afin, par exemple, de quantifier l’approvisionnement et les prédictions de pertes de rendement. Vous allez avoir besoin de pratiques de résolution de problèmes et d’amélioration continue au fil du temps pour faire face aux conditions changeantes. C’est là que la culture de l’organisation entre en jeu. Résoudre un problème une fois sans engagement envers une amélioration continue peut faire manquer à une organisation la véritable valeur de l’analyse à long terme.
Nous assistons aujourd’hui à un changement majeur vers des organisations dotées d’une infrastructure axée sur les données. Les données ne se trouvent plus uniquement dans les centres de données, mais également dans le cloud et en périphérie. Avec le processus commercial en tête, conduisant à une amélioration continue, une compréhension des affaires et des données, et jusqu’au déploiement, les organisations construites sur cette infrastructure peuvent voir un monde de différence.