#18 Datenerhebung und -aufbereitung
Subscribe to get the latest
on 2020-08-31 00:00:00 +0000
with Darren W Pulsipher,
Sarah Kalicin, Lead Data Scientist bei Intel, und Darren Pulsipher, Chief Solution Architect, Public Sector bei Intel, sprechen über den Prozess und die Vorteile der Datensammlung und -vorbereitung bei der Entwicklung einer datenzentrierten Organisation. Dies ist der zweite Schritt auf dem Weg zur datenzentrierten Organisation.
Keywords
#artificialintelligence #multicloud #process #technology
Wir brauchen Daten! Unsere Daten sind ein Durcheinander!
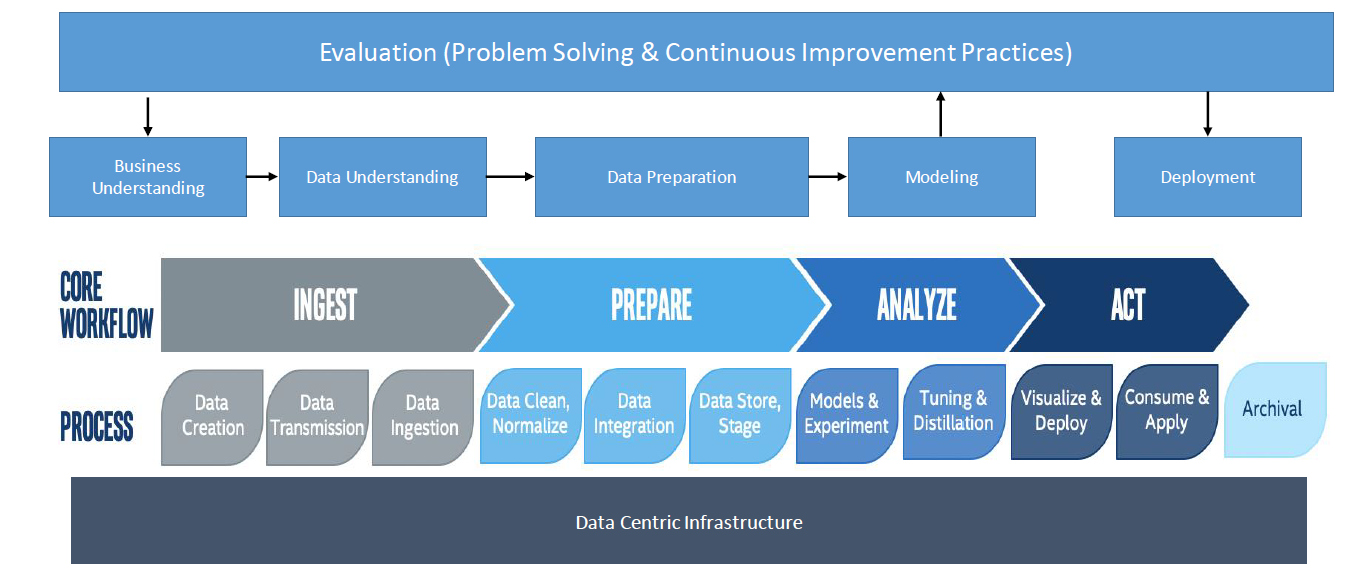
Das Erste, worüber man in diesem Teil des Prozesses nachdenken sollte, ist die Daten-Pipeline. Wie identifizieren wir die Rohdaten, die wir benötigen, und wie bringen wir sie durch die Pipeline und verwandeln sie in Erkenntnisse? Es gibt fünf wesentliche Schritte in der Pipeline: die Bestimmung des Geschäftswerts der Daten, das Eingießen, die Vorbereitung, die Analyse und schließlich das Handeln basierend auf den resultierenden Erkenntnissen.
Lassen Sie uns die Produktion als Beispiel betrachten. Bei der Bestimmung, welche Daten für ein Unternehmen von Wert sind, sollten Sie drei grundlegende Fragen stellen: Wie hoch ist die Nachfrage nach meinem Produkt? Wie ist der aktuelle Bestand? Wie hoch ist der Verlust der Ausbeute? Das sind scheinbar einfache Fragen, aber dann müssen Sie über komplexere Dinge nachdenken, wie kann ich die Nachfrage, die Produktionsfähigkeiten, den Bestand und den Ausbeuteverlust quantifizieren? Woher stammen die Daten? Wie nehme ich sie auf? Wie zuverlässig und stabil sind diese Daten? Es gibt viele Fragen und Variablen, wie die Lieferzeit des Rohprodukts, die projizierte Nachfrage und den unbekannten Ausbeuteverlust, die große Komplexität schaffen können.
Die Pipeline vereinfacht, wie all diese Komponenten zusammenkommen. Jede Art von Daten durchläuft die wichtigsten Schritte in der Pipeline, jedoch werden sie alle unterschiedlich sein. Zum Beispiel wird die Erfassung einer Art von Daten von der Erfassung einer anderen Art von Daten abweichen. Die Idee ist jedoch, alle Daten zusammenzubringen, um ein klares Bild zu erzeugen.
Wir haben Daten! Was machen wir damit?
Je nach Art der Daten und den Fragen, die Sie beantworten möchten, würden Sie unterschiedliche Analysetechniken verwenden. Zum Beispiel könnte man bei der Beantwortung der Frage, wie viele Widgets hergestellt werden sollten, durch Analyse der historischen Angebot und Nachfrage mittels Analytik und grundlegendem Business Intelligence vorgehen. Um festzustellen, welche Widgets visuelle Mängel aufweisen, könnte ein Algorithmus, der über Deep Learning Defekte in Bildern erkennt, der beste Ansatz sein. Es gibt keine Technik, die alle Probleme löst; jede ist einzigartig für das Problem und die Daten selbst.
Zusätzlich ist es wichtig, Fachexperten hinzuzuziehen, um die Muster, die die Daten liefern, besser zu verstehen. Der Fachexperte wird die Daten und deren Herkunft verstehen, und der Datenwissenschaftler wird den besten Ansatz für die Algorithmen verstehen, um mehr Erkenntnisse zu gewinnen. Wenn zum Beispiel ein Rückgang des Produktionsausstoßes durch einen maschinellen Lernalgorithmus vorhergesagt wird, wissen die Ingenieure, die das Problem beheben müssen, ohne den Kontext des Problems möglicherweise nicht, wo sie suchen sollen. Einer der Gründe, warum Organisationen nicht den erwarteten Return on Investment erzielen, ist, dass sie ihre Modelle nicht handlungsfähig gemacht haben oder nicht das Verhalten der Systeme, die sie vorhersagen möchten, widerspiegeln.
Wie all dies zusammen funktioniert, hängt von den geschäftlichen Fragen ab, die Sie stellen, und von Ihren Herausforderungen. Zum Beispiel könnten Sie eine Reihe von Algorithmen haben, die Ihnen sagen, wie viele Widgets Sie herstellen sollen. Sie könnten einen Deep Learning-Algorithmus haben, der erkennt, ob ein Widget einen Defekt aufweist und sogar die Defekte kategorisiert. Aber das hilft Ihnen nicht unbedingt weiter, wenn Sie nicht wissen, warum dieser Defekt aufgetreten ist. Sie müssen also diese Informationen mit einigen weiteren Algorithmen verknüpfen, um Korrelationen herzustellen, die die Defekte erklären, und Sie benötigen einen Aktionsplan, um das Problem zu korrigieren.
Wir müssen Erkenntnisse schaffen. Wie trainieren wir unsere Daten?
Wie erreichen wir das? Im Wesentlichen bringen Sie alle Daten zusammen, bereiten sie auf und verknüpfen sie, um zum Beispiel den Lieferbestand und die Vorhersagen zum Ertragsverlust zu quantifizieren. Sie werden im Laufe der Zeit Problemlösungs- und kontinuierliche Verbesserungspraktiken benötigen, um sich an wechselnde Bedingungen anzupassen. Hier kommt die Kultur der Organisation ins Spiel. Ein Problem einmal zu lösen, ohne sich zur kontinuierlichen Verbesserung zu verpflichten, kann dazu führen, dass eine Organisation langfristig den eigentlichen Wert der Analyse verpasst.
Wir beobachten heute einen großen Wandel hin zu Organisationen mit einer datenzentrierten Infrastruktur. Daten befinden sich nicht mehr nur im Rechenzentrum, sondern auch in der Cloud und am Netzwerkrand. Mit dem Geschäftsprozess an der Spitze, der zu kontinuierlicher Verbesserung, geschäftlichem und datenbezogenem Verständnis und letztendlich zur Implementierung führt, können Organisationen, die auf dieser Infrastruktur aufbauen, einen deutlichen Unterschied erkennen.